
Update: I have carried out some more analyses that paint a different picture to the one presented below. Oops!
A recently accepted paper by Keith Chen has been getting a lot of press coverage. Chen has discovered a close link between the properties of the language people speak and their economic decisions. People who speak languages which mark the future tense differently to the present tense tend to make fewer provisions for the future. This includes economic decisions such as being less likely to save money, but also secondary indicators such as greater prevalence of smoking and obesity.
The hypothesis is that marking the future tense differently makes the future seem further away, and therefore you are less likely to plan for the future.
Chen has talked about this hypothesis at a TED conference and has been covered in the media, most recently in a BBC economics column (which, to be fair, was fairly critical). The hypothesis has been criticised by several linguists, notably on language log (and a great model post by Mark Liberman), where Chen gave a response. The data has been criticised (e.g. English is marked as ‘strong future tense marking’, but has a range of ways of using present tense for future time reference), as well as the thinking behind the hypothesis itself (e.g. why wouldn’t marking a difference in the language actually make the future MORE salient?). Some have also pointed out weaknesses in the statistical claim, for instance, Östen Dahl has pointed out that speaking a language with front rounded vowels is also a good predictor of economic decisions.
Here at Replicated Typo, we have discussed many cases of spurious correlations – statistical links between cultural traits that are unlikely to be causal. James Winters and I recently published a paper on the dangers of making claims based on large-scale, cross-cultural statistics. Basically, it’s very easy to find statistical links between any two variables because cultrual traits are inherited in bundles (they are not independent).
In this post, I address an issue that I haven’t seen systematically answered yet: Chen predicts that there is a correlation between future tense marking and economic decisions, and finds a strong link. However, he should also predict that future tense marking is a stronger predictor than other linguistic variables. In other words, can we find a different aspect of language that is even better at predicting economic behaviour? Here I test the link between the propensity to save money and many different linguistic factors.
Looking for correlations
I used the world values survey, used by Chen, to compare the propensity to save money with 144 features from the world atlas of language structures. For each linguistic variable, I ran a linear regression with propensity to save money as the dependent variable and independent variables including the linguistic variable, age, sex, employment status, marriage status, religion, number of children and survey year. I compared the F-statistic (goodness of model fit) for each regression. This is the same approach as in Chen’s analysis.
The future tense marking variable had an F-statistic greater than 65% of the linguistic variables. Below is a histogram of the resulting F-statistics with a red line indicating the strength of the future tense variable.
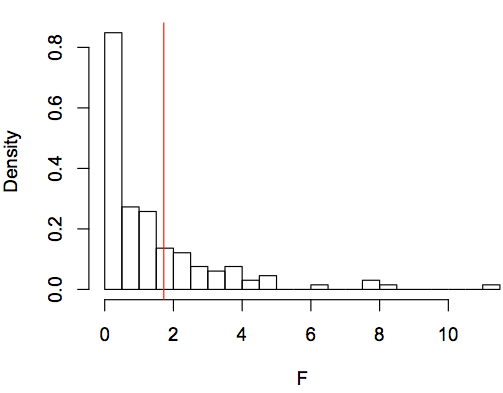
Here are ten best linguistic variables for predicting economic decisions:
- Uvular Consonants
- Third Person Zero of Verbal Person Marking
- Order of Relative Clause and Noun
- Alignment of Verbal Person Marking
- M-T Pronouns
- Ditransitive Constructions: The Verb Give
- Position of Interrogative Phrases in Content Questions
- Indefinite Pronouns
- Order of Degree Word and Adjective
- Tone
And here are some graphs demonstrating links between economic decisions and linguistic variables:
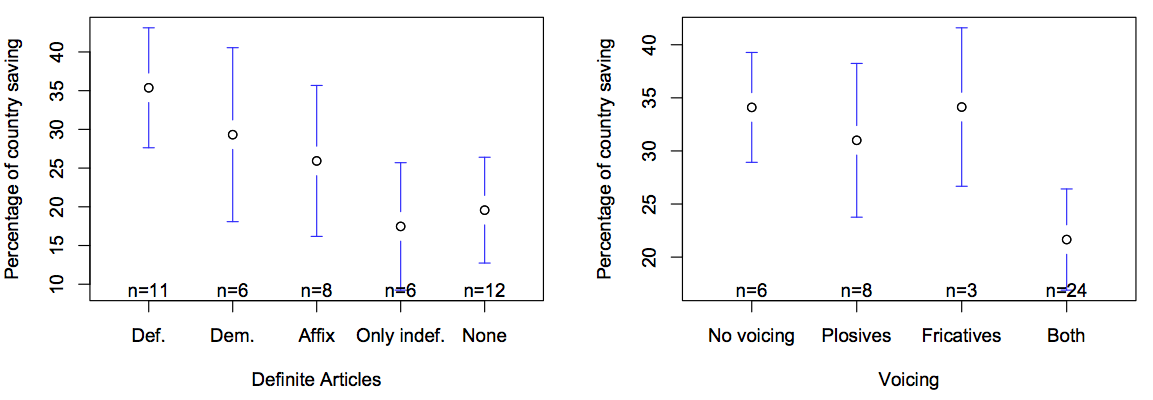
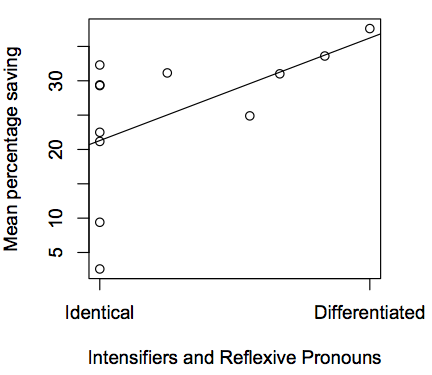
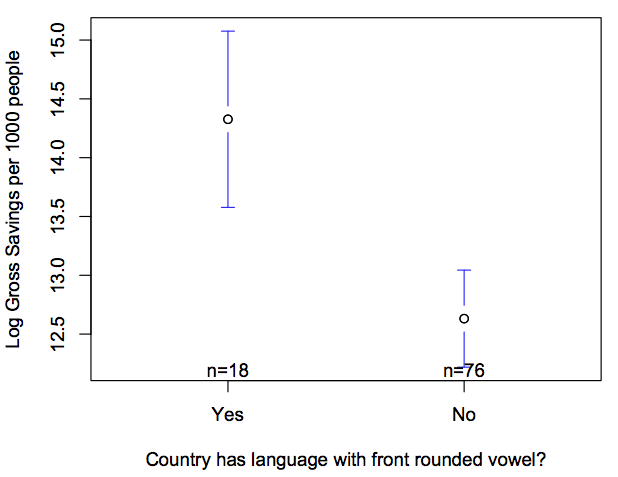
Doing the analysis by aggregating over language families produces a similar result: the future tense variable has an F-score greater than 70% of the linguistic variables.
In contrast to Chen’s hypothesis, linguistic variables that have nothing to do with concepts of time are equally good at predicting economic decisions. That is, a hypothesis that linked the presence of uvular consonants to economic decisions would have equal statistical support as the ‘Whorfian economics’ hypothesis. It’s quite difficult to imagine a causal reason for such a link (indeed, I’m claiming that there isn’t a direct causal link), and so Chen’s hypothesis seems more plausible. But then the question arises: what is the role of statistical analyses in evaluating hypotheses?
James Winters and I argue that statistical analyses can help generate, motivate and explore hypotheses. However, they have weaknesses that need to be supported by other methods such as experiments, models and theoretical work (Roberts & Winters, 2012). Chen has recently tested his hypothesis looking at uses of morphological future tense marking in weather reports (here). While this is impressive, it still relies on large-scale, cross-cultural statistics. It would be interesting to see whether economic decisions could be manipulated in a lab experiment by priming different expressions of time (e.g. Chen’s example of “Rain is likely this weekend.”:present tense ‘is’, versus “It will likely rain this weekend.”: future tense ‘will rain’). I’d be surprised if someone isn’t already running this experiment.
Change over time
Another point I’d like to raise is the variation in economic decisions over time. Below are some graphs illustrating the change in economic decisions within linguistic groups:
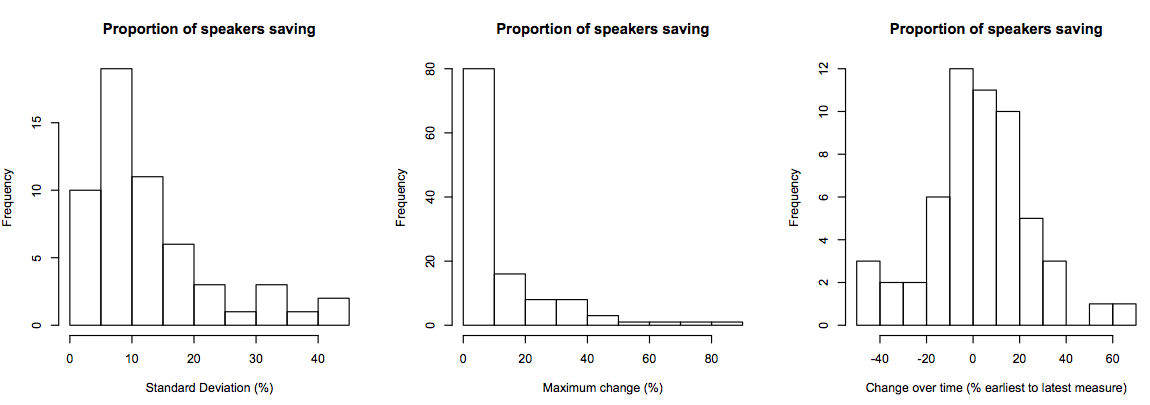
The proportion of people speaking a given language can change by up to 80% over the years the survey was carried out. For example, 100% of Italian speakers were saving money in 1997, compared to 18.4% in 2000. This gives an idea of how small the effect of language might be.
Conclusion
There is a strong statistical link between future tense marking and economic decisions. This is an intriguing finding, and Chen’s hypothesis is very interesting and deserves further research. However, this link may not be significantly greater than links between other cultural traits, so there’s no principled reason to highlight this link in particular without further evidence.
Without a more fleshed-out theory of how linguistic categorisation of time is related to perception of time, this kind of approach risks damaging the reputation of more sophisticated work on linguistic relativity, and also the reputation of economics. More importantly, misinterpretations of this work could lead to changes in public perception and policy. For example, one journalist covered the story using the title “Want to end the various global debt crises? Try abandoning English, Greek, and Italian in favor of German, Finnish, and Korean.”
References
Chen, M. (2011). The Effect of Language on Economic Behavior: Evidence from Savings Rates, Health Behaviors, and Retirement Assets SSRN Electronic Journal DOI: 10.2139/ssrn.1914379
Chen’s paper can be read here
Roberts, S. & Winters, J. (2012). Social Structure and Language Structure: the New Nomothetic Approach. Psychology of Language Learning, 16 (2), 89-112 : 10.2478/v10057-012-0008-6
Cool post as usual Sean. Just one point regarding this: “Basically, it’s very easy to find statistical links between any two variables because cultrual traits are inherited in bundles (they are not independent).” I think too much has been made of this issue and it somewhat sidetracks from an even more salient, albeit related, point concerning these correlational studies: that as data sets grow larger, so too do the number of spurious correlations. It is the tragedy of big data.
As Nassim Nicholas Taleb recently put it: “There is a certain property of data: in large data sets, large deviations are vastly more attributable to noise (or variance) than to information (or signal) […] The more variables, the more correlations that can show significance in the hands of a “skilled” researcher. Falsity grows faster than information; it is nonlinear (convex) with respect to data” (Taleb, 2012: 417).
More broadly, it applies generally to the growth in information we’re seeing — for example, fewer and fewer papers are replicable in terms of results, and this is because we’re seeing more data, more information and, most importantly, more false information.
Excellent comments! This whole story is a bit traumatic for me since I see my own work being used in a way that I am not really very happy with. I did not expect my “15 minutes of fame” to look like this! Anyway, last night I tried looking at things from another angle, but along the same line of thinking, it seems. It is not only the case that there are many different linguistic features that can predict economic behavior, but Chen’s division of languages into “strong and weak FTR” ones also predicts various other pieces of behavior. Already health parameters such as grip strength and peak expiratory flow, included by Chen among the effects of grammaticalized FTR, cast the net rather widely. What I did was to take the OECD countries in Chen’s Figure 2 and compare the “grey” (FTR-marking) ones with the white (futureless) ones on two parameters, intentional homicide rates and belief in God, using statistics from Wikipedia. (In the latter case, I restricted the comparison to European countries, since there were no exactly comparable figures for the others). It turned out that there is a massive difference in homicide rates, especially if you weight the countries according to their population, and a marked but smaller difference in how many people said that they believe in a (personal) God. (I can provide figures but it takes some work that I have no time for at the moment.) One important factor here is that at least in the OECD statistics, the countries of northern Europe (and also Japan) weigh very heavily among the “futureless” ones. In the end, Max Weber may have more to say here than Keith Chen.
@Wintz: You’re right, of course! I suppose the non-independence of cultural variables is just more theoretically interesting to me, or the more-data-means-more-error concept is just too depressing!
@Prof. Dahl: This is really interesting! It seems that it’s difficult to get a grip on causality in large-scale datasets without a strong guiding theory, especially when one can keep adding variables (when should researchers STOP adding variables?). As your analysis shows, the strong/weak future tense distinction is linked with SOME KIND OF cultural tendencies, but it seems too easy to link it to a specific variable and make a story out of it.
I reckon the days of making a prediction about a single dependent variable are coming to a close. With the amount of data now available, researchers should be making predictions about networks of relationships between variables.
One way to explore the relationship between lots of variables is using Bayesian Causal Graphs. I use them to look at a similar database here: http://www.replicatedtypo.com/the-final-correlation-bayesian-causal-graphs-as-an-alternative-to-phylogenetics/5616.html The R library pcalg can generate these fairly easily, here’s a tutorial: http://cran.r-project.org/web/packages/pcalg/vignettes/pcalgDoc.pdf
Hi Sean, a few thoughts on this post, which I think is an interesting analysis. To be clear to readers though, I think there are a number of important differences between the analysis you do here and the one I do in my paper here:
http://faculty.som.yale.edu/keithchen/papers/LanguageWorkingPaper.pdf
1) The regression analysis you perform (OLS) is not the regression form I use in the in the majority of my paper. This is because when studying binary outcomes (like saving or not saving in a given year) OLS is both a biased and inefficient estimator.
2) There are a few regressions on continuous measures (like accumulated retirement savings) that I do study using OLS, and those may be useful to compare to your analysis: the average F-statistic for those regressions in cross-country data is 272 (table 6 in my paper). It’s a different setting than the one you study, but I think it may be at least partially informative; the scale you report F-statistics for runs from 0 to 10, and the statistic you report for your analysis of the WALS future measure is less than 2.
3) One reason for this discrepancy is that the FTR variable I study in my paper is not included in the set you study (unless I misread your post). The future tense marking variable you use from the WALS is whether a language has an inflectionally marked future. This not the weak-FTR measure I study in my paper, though they are correlated. My analysis agrees with yours in this regard; in my paper (Online Appendix Table 4) I report that the WALS measure does not have a independently significant effect on savings rates when studied with the levels of controls I include. To be clear though, this is not the variable I study.
This is not to say that I disagree with the spirit of your analysis; I like the thought and think the logic behind it could be carried even farther. What about doing the following: take savings behavior, and regress it on a number of important economic and demographic controls. From that regression, form residuals, and then use that as the independent variable in a regression with many different linguistic features, all simultaneously studied as dependent variables. That is, look at the component of savings that is unexplained by demographics, and ask which linguistic variables, taken as a whole, seem to explain that unexplained component.
That’s just a suggestion though, overall I think it’s an interesting idea that you’re working on here.
@Prof. Chen: Many thanks for your reply! It’s been a while since I read your original paper (and I did this analysis in September, so it’s not fresh in my mind either!).
Re 1): This is a good point, the regressions above are for a mix of binary and continuous variables. I’m currently working on coding the variables in WALS correctly. I’m also not considering the interactions here. I just noticed that there are some other differences, too, such as cutting age into 10-year bins, while I used the continuous age range. I just wanted an idea of the relative strength of the FTR in comparison to other linguistic measures, so while the analysis above may not be the same, it does indicate that other WALS features should predict saving decisions.
Re 2): The results for the continuous measures in your study are impressive, and it’s interesting to see the same result crop up for many kinds of economic decisions. I don’t doubt that there is a strong link between FTR and saving decisions, I’m just wondering if the story is as precise as your hypothesis suggests. I would think that the causal story behind these links is quite complex. One method that I mentioned above that might help is Bayesian Causal Graphs. This would be a way of testing whether FTR and saving behaviour are directly linked, or mediated by other factors. (see http://www.replicatedtypo.com/the-final-correlation-bayesian-causal-graphs-as-an-alternative-to-phylogenetics/5616.html)
Yes, the F-scores here only make sense as relative to others in my study.
Re 3): Sorry, I wasn’t clear – the FTR variable in the analysis above comes from your paper (Online Appendix Table 5). It’s interesting that you find that the WALS morphological future tense variable has no independent effect – my analysis above would not predict that.
Your suggestion of looking at which linguistic variables explain the residual variation in a model with non-linguistic variables is a great idea. I’ll try and find time to run this.
Another test I tried was controlling for language relatedness: For each pair of languages I calculated the distance between the FTR variable, the difference in proportion of speakers saving and the patristic distances on the language phylogenetic tree as defined in the Ethnologue. The plan was to use partial mantel tests to control for linguistic relatedness. However, there were many languages that I failed to get this data for, and the analysis didn’t really have enough power to be informative. I also tried using phylogenetic tools to test the link between the two variables, but I’m not an expert on this technique and I don’t think there was enough data. A more sustained attempt might bear fruit, though!
As me and James discuss in our paper, these kinds of studies can be a catalyst for getting people from different fields talking to each other – and in the case of your study, this has been quite effective, and has mainly taken place online in open forums. Given that this is one of the most publicised studies of its kind, it’s important that it be seriously considered, so many thanks for the helpful comments!
Update: I’ve carried out some of Chen’s suggestions and find quite different results.
http://www.replicatedtypo.com/whorfian-economics-reconsidered-residuals-and-causal-graphs/6011.html
Sean, you’re молодец. I was looking for second opinions and theories similar to Chen’s before trying to unlearn the future tense to save more money. You saved me a lot of effort and gave much more information to savor.
Thank you for that.