This is a guest post by Justin Quillinan (of Chimp Challenge fame).
Cast your reminisce pods back a few days and recall Sean’s iterated learning experiment using the automated transcription of YouTube videos. The process went as follows:
1. Record yourself saying something.
2. Upload the video to YouTube
3. Let it be automatically transcribed (usually takes about 10 minutes for a short video)
4. Record yourself saying the text from the automatic transcription
5. Go to 2
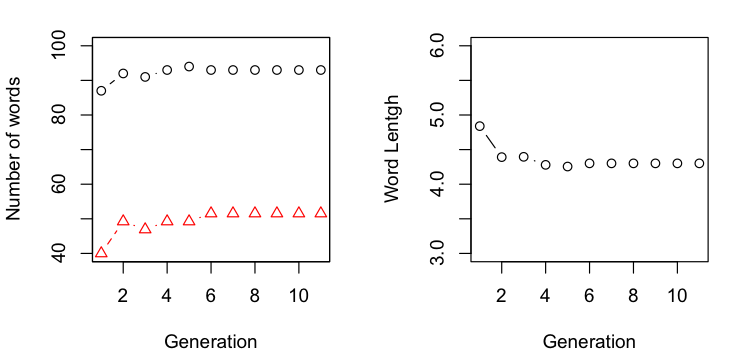
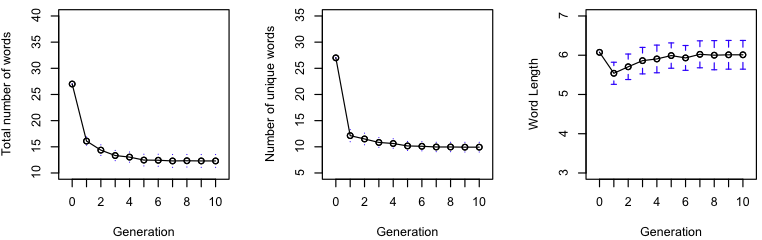
Sean took a short extract from Kafka’s Metamorphosis and found that, as in human iterated learning experiments, both the error rate and compression ratio decreases with successive iterations. He also found that the process resulted in a text with longer and more unique words.
I was curious to see whether we could remove human participants entirely and run computer generated speech through this automated transcription. Here’s the process:
1. Generate an audio file from some text using a speech synthesis program;
2. Generate a transcription of the audio file;
3. Repeat from 1. with the new transcription.
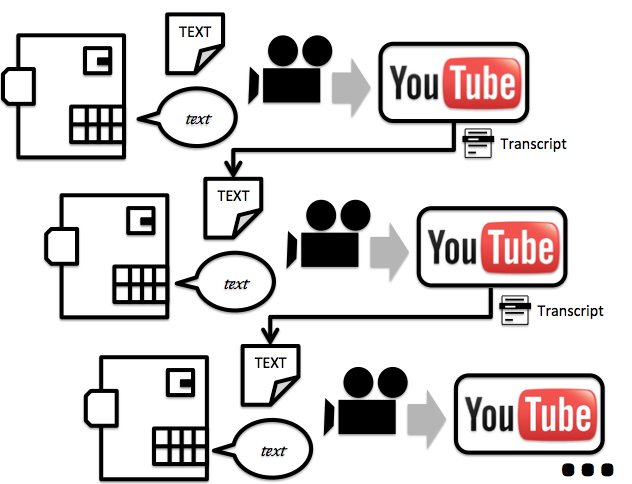
For speech synthesis I used Festival, and for transcription I used an undocumented Google API that is presumably used in the YouTube transcription (here’s the code: ilm.sh). One thing to note is that this API only accepts short files, so longer passages had to be bitten off into red ball like sections.
Here’s the first few sentences of Metamorphosis:
One morning, as Gregor Samsa was waking up from anxious dreams, he discovered that in his bed he had been changed into a monstrous verminous bug. He lay on his armour-hard back and saw, as he lifted his head up a little, his brown, arched abdomen divided up into rigid bow-like sections. From this height the blanket, just about ready to slide off completely, could hardly stay in place. His numerous legs, pitifully thin in comparison to the rest of his circumference, flickered helplessly before his eyes.
And here’s what we get after one iteration:
wine bar in the ass cracker Samsung was waking up from my chest remains the discover about in his bed he had been changed into a monstrous reminisce pod. delay on his armor hard back and saw as he lifted his head off a little is brown autobell me to bite it off into red ball like sections. from the title blanket just about ready to slide off completely could hardly stay in place. his numerous legs pitifully Finn in comparison to the rest of his circumference Flipkart helplessly before his eyes
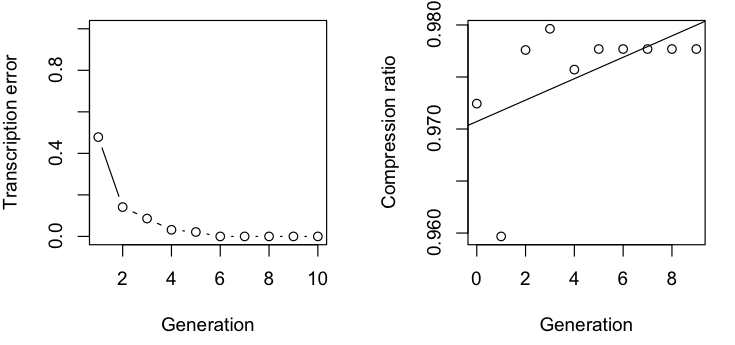
Given that there is far less variability in computer generated than human produced speech, we would expect that the process would rapidly converge to little or no error. After only five iterations, we get a stable state with no transcription error and the text:
wine bar in class cracker Samsung was waking up from my chest remains the discover about in his bed he has been changed into a monster some other spot. delay on his armor hardback and so has he left his head off a little is brown Autoblow me to bite it off at the Red Bull like sections. from the title blanket just about ready to slide off completely could hardly stay in place. his numerous legs pitifully Finn and comparison to the rest of his circumference flipped out Leslie before his eyes.
What’s immediately interesting is the number of brand names that are produced, in this and other samples I tried. Google being Google this is perhaps not surprising, but it does give a further insight into the biases of their algorithms and the limitations for their use as trustworthy models in these kinds of experiments. I would suggest the rule that anything repeatedly passed through an advertising company rapidly converges to spam.
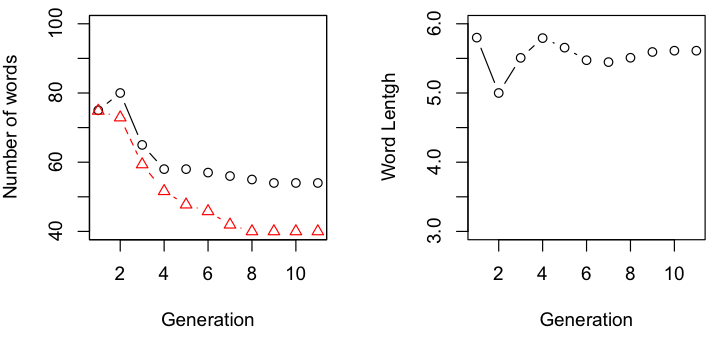
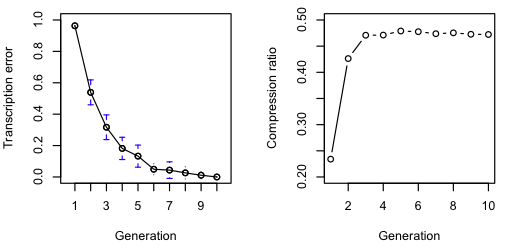
As with Sean’s production, the error rate decreases with successive iterations. In contrast to Sean’s production, however, the compression ratio actually increases. In addition, this process resulted in an increase in the number of words and decrease in average word length. This suggests that the bias for word length might be more affected by the production than the transcription.
However, since Metamorphosis was originally written by Kafka in German, the passage we used had already passed through at least one level of production and transcription before we started. Here’s the actual original passage:
Als Gregor Samsa eines Morgens aus unruhigen Träumen erwachte, fand er sich in seinem Bett zu einem ungeheueren Ungeziefer verwandelt. Er lag auf seinem panzerartig harten Rücken und sah, wenn er den Kopf ein wenig hob, seinen gewölbten, braunen, von bogenförmigen Versteifungen geteilten Bauch, auf dessen Höhe sich die Bettdecke, zum gänzlichen Niedergleiten bereit, kaum noch erhalten konnte. Seine vielen, im Vergleich zu seinem sonstigen Umfang kläglich dünnen Beine flimmerten ihm hilflos vor den Augen.
And here’s what we get after nine iterations of German production and transcription (note that because of the limitations of the API discussed above I had to break the text not just at sentence boundaries but also after the phrase “geteilten Bauch”):
Amazon sind morgen Samsung Wave 2 Vapiano Markt Pforzheim Bett beiden Mannschaften. Wetter Santander an den Weihnachtsmann corporate website and merry christmas for my life and style, auf der Schanz jetzt ein Bett bei dem Fensterbrett steht gar nicht arbeiten bei den wecker how to upgrade. browser Android erscheint Samstag im Fernsehen Transformation morgen.
Again with the spam, and we still see a decrease in error and increase in compression ratio.
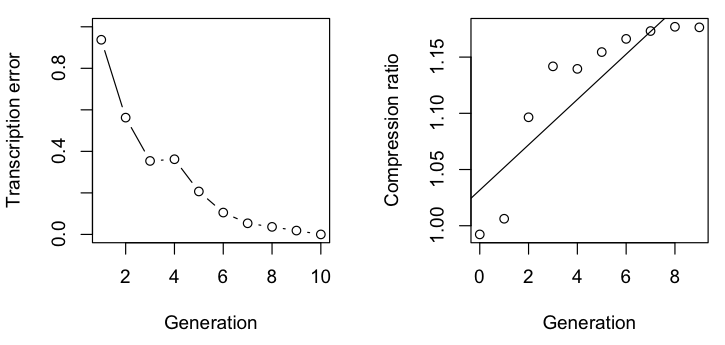
It differs from the English chain in other ways. German takes longer to converge (nine generations vs. five) and results in fewer words than the original text, though it’s unclear whether these words are significantly longer or shorter
Typically in iterated learning experiments we don’t begin with such structured initial data, but with random unstructured strings like the following:
nehomami wumaleli mahomine maholi wupa wuneho lemi manehowu nepa wunene maho howu nemine lemilipo hopa lemipo nehowu nemi lipapo lilema pohomali pamamapo wulepami lepali poliho powuma lemaho
(Kirby, Cornish & Smith, 2008)
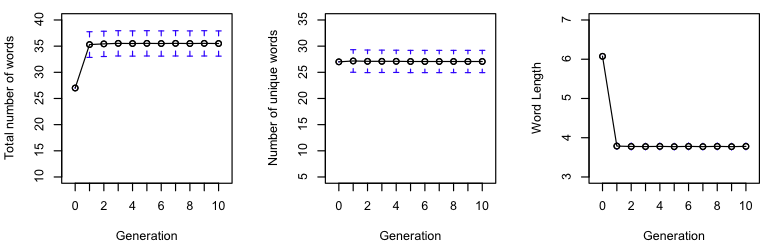
Taking 30 random permutations of the above initial data I ran 30 chains for ten generations in both English and German. The above string itself yields:
I hope mommy will email the holy holy holy place the whole house full of people no hold me like a polar pop the Molly pop over the popular poly-poly hope out of my hoe
We see similar trends here as for the literary samples above. Both languages show a decrease in error and increase in compression ratio over generations. For the English translation chains, the number of words increases while the average word length decreases. For the German translation, the number of words decreases, while the average word length stays more or less constant.
For the English transcription
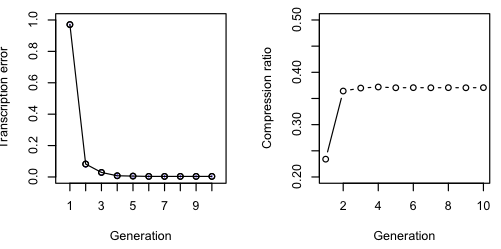
For the German transcription
Using computational speech synthesis reduces the variability in production, and allows us to more accurately investigate the inductive biases of the transcription algorithm. The differences we see in English and German transcription suggest that many biases may be introduced not through some hard coded algorithm but by the data used to train it. Much like human language.
Merry christmas for my life and style,
Justin
Interesting application of the ILM, I like it! (-: