Back in March 2014, Hedvig Skirgård and I wrote a post about the Great Language Game. Today we’ve published those results in PLOS ONE, together with the Game’s creator Lars Yencken.
One of the fundamental principles of linguistics is that speakers that are separated in time or space will start sound different, while speakers who interact with each other will start to sound similar. Historical linguists have traced the diversification of languages using objective linguistic measurements, but so far there has never been a widespread test of whether languages further away on a family tree or more physically distant from each other actually sound different to human listeners.
An opportunity arose to test this in the form of The Great Language Game: a web-based game where players listen to a clip of someone talking and have to guess which language is being spoken. It was played by nearly one million people from 80 countries, and so is, as far as we know, the biggest linguistic experiment ever. Actually, this is probably my favourite table I’ve ever published (note the last row):
| Continent of IP-address | Number of guesses |
|---|---|
| Europe | 7,963,630 |
| North America | 5,980,767 |
| Asia | 841,609 |
| Oceania | 364,390 |
| South America | 356,390 |
| Africa | 74,032 |
| Antarctica | 11 |
We calculated the probability of confusing any of the 78 languages in the Great Language Game for any of the others (excluding guesses about a language if it was an official language of the country the player was in). Players were good at this game – on average getting 70% of guesses correct.
Using partial Mantel tests, we found that languages are more likely to be confused if they are:
- Geographically close to each other;
- Similar in their phoneme inventories
- Similar in their lexicon
- Closely related historically (but this effect disappears when controlling for geographic proximity)
We also used Random Forests analyses to show that a language is more likely to be guessed correctly if it is often mentioned in literature, is the main language of an economically powerful country, is spoken by many people or is spoken in many countries.
We visualised the perceptual similarity of languages by using the inverse probability of confusion to create a neighbour net:
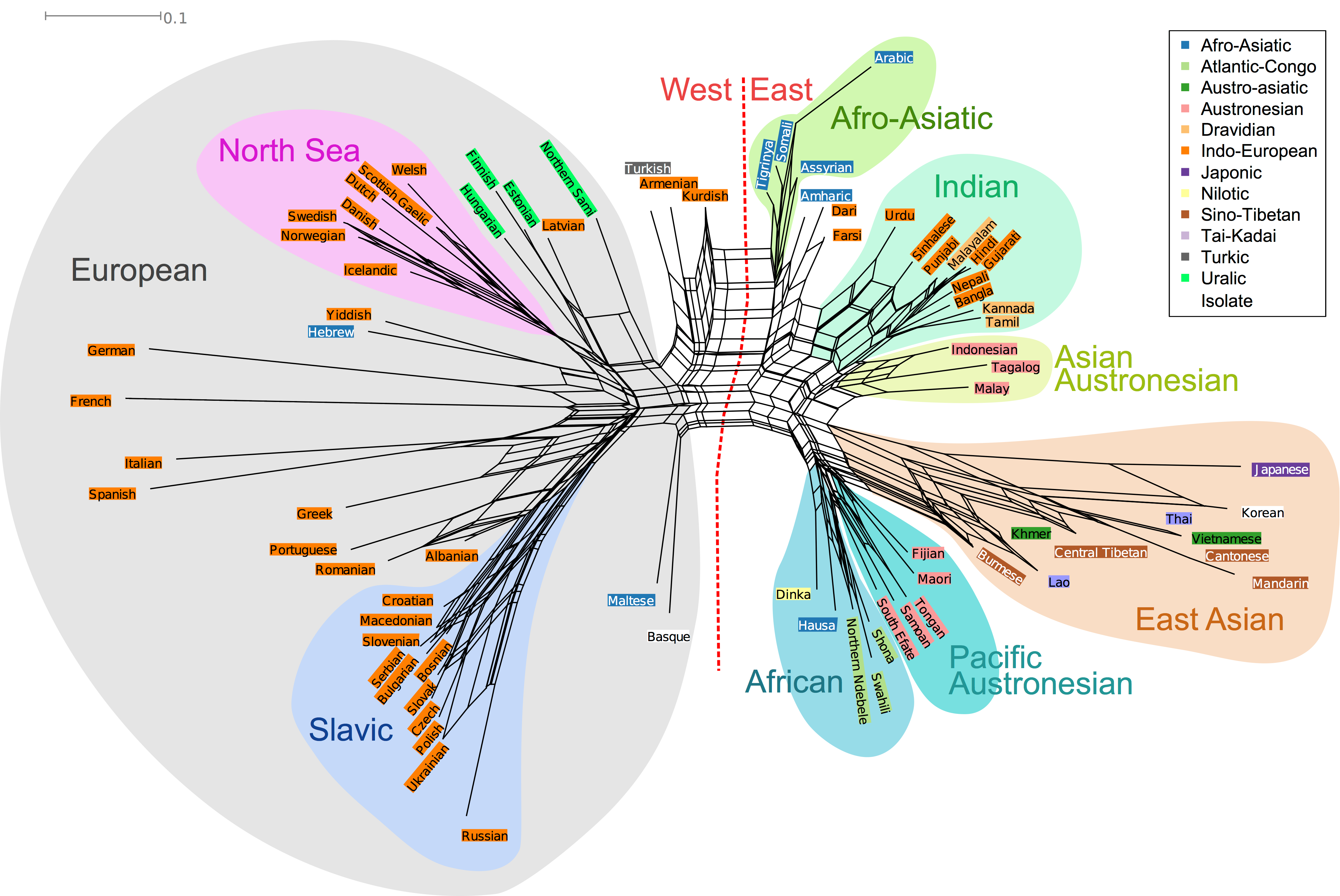
This diagram shows a kind of subway map for the way languages sound. The shortest route between two languages indicates how often they are confused for one another – so Swedish and Norwegian sound similar, but Italian and Japanese sound very different. The further you have to travel, the more different two languages sound. So French and German are far away from many languages, since these were the best-guessed in the corpus.
The labels we’ve given to some of the clusters are descriptive, rather than being official terms that linguists use. The first striking pattern is that some languages are more closely connected than others, for example the Slavic languages are all grouped together, indicating that people have a hard time distinguishing between them. Some of the other groups are more based on geographic area, such as the ‘Dravidian’ or ‘African’ cluster. The ‘North Sea’ cluster is interesting: it includes Welsh, Scottish Gaelic, Dutch, Danish, Swedish, Norwegian and Icelandic. These diverged from each other a long time ago in the Indo-European family tree, but have had more recent contact due to trade and invasion across the North Sea.
The whole graph splits between ‘Western’ and ‘Eastern’ languages (we refer to the political/cultural divide rather than any linguistic classification). This probably reflects the fact that most players were Western, or at least could probably read the English website. That would certainly explain the linguistically confused “East Asian” cluster. There are also a lot of interconnected lines, which indicates that some languages are confused for multiple groups, for example Turkish is placed halfway between “West” and “East” languages.
It was also possible to create neighbour nets for responses from specific parts of the world. While the general pattern is similar, there are also some interesting differences. For example, respondents from North America were quite likely to confused Yiddish and Hebrew. They come from different language families, but are spoken by a mainly Jewish population and this may form part of players’ cultural knowledge of these languages.
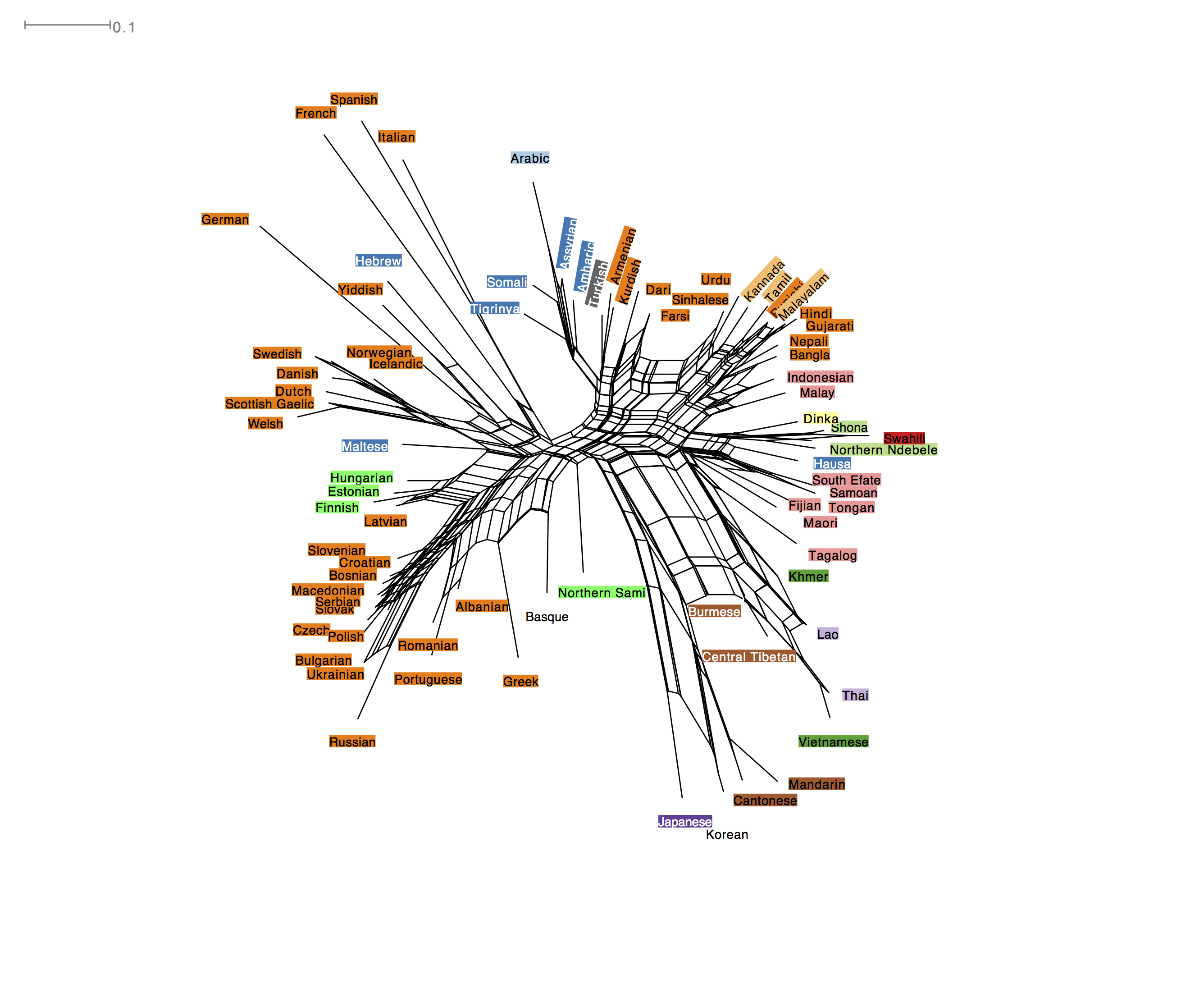
In contrast, players from African placed Hebrew with the other Afro-Asiatic languages.
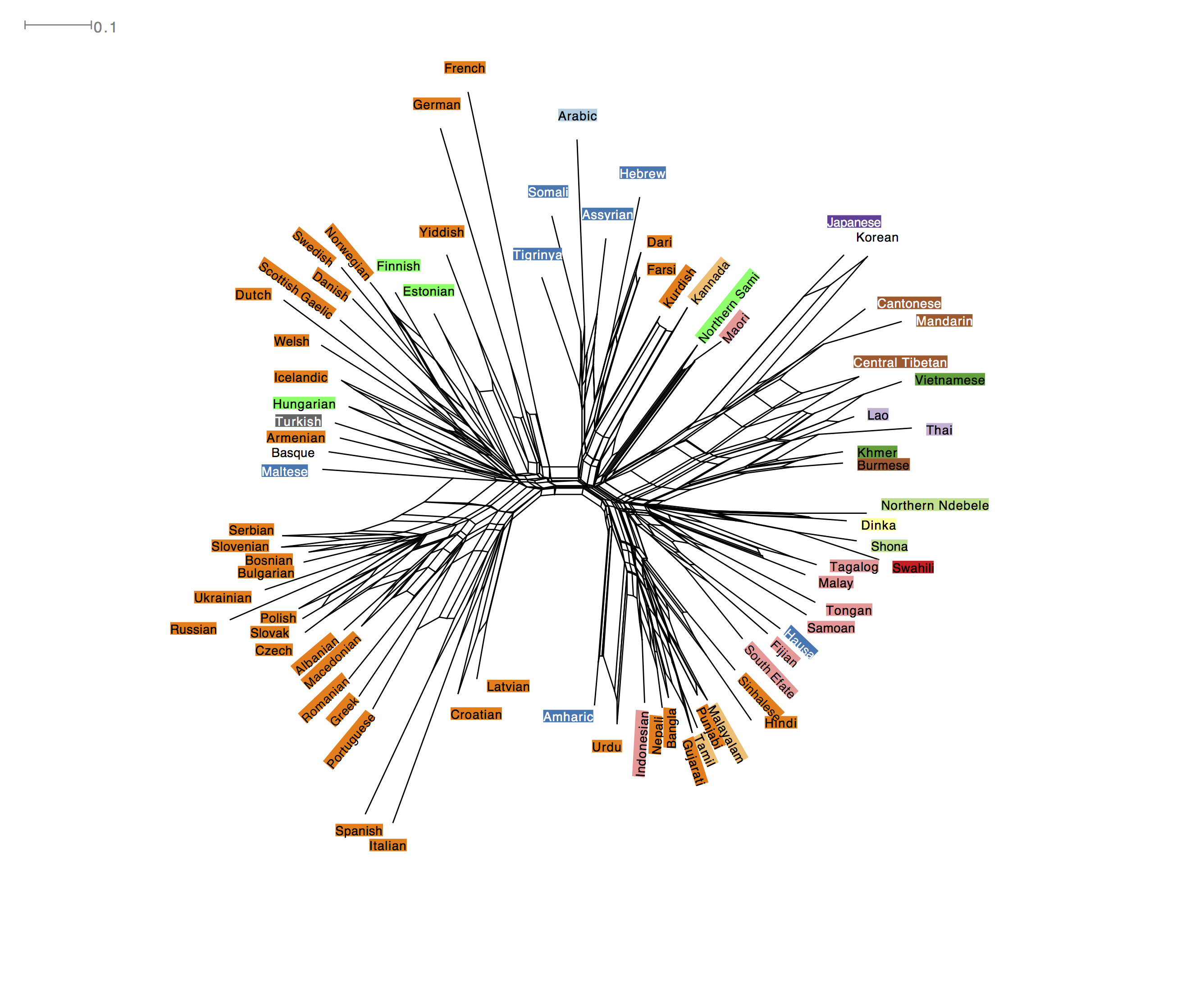
Results like this suggest that perception may be shaped by our linguistic history and cultural knowledge.
We also did some preliminary analyses on the phoneme inventories of languages, using a binary decision tree to explore which sounds made a language distinctive. Binary decision trees identified some rare and salient features as critical cues to distinctiveness.
The future

The analyses were complicated because we knew little about the individuals playing beyond the country of their IP address. However, Hedvig and I, together with a team from the Language in Interaction consortium (Mark Dingemanse, Pashiera Barkhuysen and Peter Withers) create a version of the game called LingQuest that does collect people’s linguistic background. It also asks participants to compare sound files directly, rather than use written labels.
You can download LingQuest as an apple App, or play it online here.
Yiddish is a mixed language with ~20% of its vocabulary from Hebrew (70% German and 10% Slavic). Given how few people have any cultural knowledge about Yiddish or have ever even heard Yiddish, let alone heard of it, that’s the far more likely explanation of the confusion.
Good point, but the difference between populations is still interesting.
The charts confirm what I’ve always suspected, that (to the uninitiated) Portuguese sounds more like a Slavic language than a Romance language. Interesting to see Romanian in a similar position, and especially interesting that this mistake is apparently not made by Africans!
Yes, Hedvig made the same observation!
Yeah, very much. It might depend a lot on who in Africa was answering. North & East Africans (Arabic, Afro-Asiatic) may explicitly know that Hebrew is Semitic. What does everyone else (e.g., Asia or S America) say?
That’s an interesting visualization. What’s this type of graph called?
It’s a Neighbour Net. You can make them with splitstree: http://www.splitstree.org/
This is really cool!
To clarify, is geographical proximity a better predictor of confusability than common ancestry?