As I mentioned in my previous post, the 2012 Poznań Linguistic Meeting (PLM) features a thematic section on “Theory and evidence in language evolution research.” This section’s invited speaker was Jim Hurford, who is Emeritus Professor at Edinburgh University. Hurford is a very eminent figure in language evolution research and has published two very influential and substantive volumes on “Language in the Light of Evolution”: The Origins of Meaning (2007) and The Origins of Grammar (2011).
In his Talk, Hurford asked “What is wrong, and what is right, about current theories of language, in the light of evolution?” (you can find the abstract here).
Hurford presented two extreme positions on the evolution of language (which nevertheless are advocated by quite a number of evolutionary linguists) and then discussed what kinds of evidence and lines of reasoning support or seem to go against these positions.
Extreme position A, which basically is the Chomskyan position of Generative Grammar, holds that:
(1) There was a single biological mutation which (2) created a new unique cognitive domain, which then (3) immediately enabled the unlimited command of complex structures via the computational operation of merge. Further, according to this extreme position, (4) this domain is used primarily for advanced private thought and only derivatively for public communication and lastly (5) it was not promoted by natural selection.
On the other end of the spectrum there is extreme position B, which holds that:
(1) there were many cumulative mutations which (2) allowed the expanding interactions of pre-existing cognitive domains creating a new domain, which however is not characterized by principles unique to language. This then (3) gradually enabled the command of successively more complex structures. Also, on this view, this capacity was used primarily for public communication, and only derivatively for advanced private thought and was (5) promoted by natural selection.
Hurford then went on to discuss which of these individual points were more likely to capture what actually happened in the evolution of language.
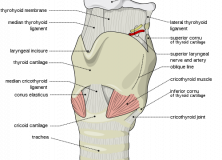
He first looked at the debate over the role of natural selection in the evolution of language. In Generative Grammar there is a biological neurological mechanism or computational apparatus, called Universal Grammar (UG) by Chomsky, which determines what languages human infants could possibly acquire. In former Generative Paradigms, like the Government & Binding Approach of the 1980s, UG was thought to be extremely complex. What was more, some of these factors and structures seemed extremely arbitrary. Thus, from this perspective, it seemed inconceivable that they could have been selected for by natural selection. This is illustrated quite nicely in a famous quote by David Lightfoot:
“Subjacency has many virtues, but I am not sure that it could have increased the chances of having fruitful sex (Lightfoot 1991: 69)”