Professor Russell Gray (University of Auckland, New Zealand) will present his work on the evolution of language, culture and cognition at the annual Nijmegen Lectures in January 2014.
In the Nijmegen lectures series, a leading scientist in the fields of psychology or linguistics presents a three-day series of lectures and seminars. The purpose of the series is to allow broad and intensive coverage of research topics by providing extensive interaction among the invited speaker and the participants. The series is a collaborative activity of the Max Planck Institute for Psycholinguistics, the Donders Institute and the Radboud University Nijmegen.
Call for posters
The Nijmegen Lectures will include a poster session on topics related to this year’s theme: Evolution of language, culture and cognition. We invite submissions of abstracts for posters, particularly from junior researchers, and especially studies relating to the theme of the lectures.
Please submit an abstract of no more than 300 words by email to sean.roberts@mpi.nl. Please include a title, authors, affiliations and contact email addresses (not included in the word count). The deadline is November 15th, 2013. Abstracts will be moderated by the Nijmegen lectures committee and candidates will be informed of decisions by November 29th.
The poster session will take place on January 28th from 16:30-18:00. We remind candidates that admission to the Nijmegen lectures is free, but registration is required for the afternoon discussion sessions. Please visit http://www.mpi.nl/events/nijmegen-lectures-2014 for more details. We regret that we cannot offer financial support to candidates.
Lately, I took time out to read through a few papers I’d put on the backburner until after my first year review was completed. Now that’s out of the way, I found myself looking through Berwick et al.‘s review on Evolution, brain, and the nature of language. Much of the paper manages to pull off the impressive job of making it sound as if the field has arrived on a consensus in areas that are still hotly debated. Still, what I’m interested in for this post is something that is often considered to be far less controversial than it is, namely the notion of mental representations. As an example, Berwick et al. posit that mind/brain-based computations construct mental syntactic and conceptual-intentional representations (internalization), with internal linguistic representations then being mapped onto their ordered output form (externalization). From these premises, the authors then arrive at the reasonable enough assumption that language is an instrument of thought first, with communication taking a secondary role:
In marked contrast, linear sequential order does not seem to enter into the computations that construct mental conceptual-intentional representations, what we call ‘internalization’… If correct, this calls for a revision of the traditional Aristotelian notion: language is meaning with sound, not sound with meaning. One key implication is that communication, an element of externalization, is an ancillary aspect of language, not its key function, as maintained by what is perhaps a majority of scholars… Rather, language serves primarily as an internal ‘instrument of thought’.
If we take for granted their conclusions, and this is something I’m far from convinced by, there is still the question of whether or not we even need representations in the first place.If you were to read the majority of cognitive science, then the answer is a fairly straight forward one: yes, of course we need mental representations, even if there’s no solid definition as to what they are and the form they take in our brain. In fact, the notion of representations has become a major theoretical tenet of modern cognitive science, as evident in the way much of field no longer treats it as a point of contention. The reason for this unquestioning acceptance has its roots in the notion that mental representations enriched an impoverished stimulus: that is, if an organism is facing incomplete data, then it follows that they need mental representations to fill in the gaps.
That’s a guest post I’ve contributed to Language Log. The disciplines are literary criticism on the one hand, and computational linguistics on the other. Here’s an abstract:
Though computational linguistics (CL) dates back to the first efforts in machine translation in the mid 1950s, it is only in the last decade or so that it has had a substantial impact on literary studies through the statistical techniques of corpus linguistics and data mining (know as natural language processing, NLP). In this essay I briefly review the history of computational linguistics, from its early days involving symbolic computing to current developments in NLP, and set that in relationship to academic literary study. In particular, I discuss the deeply problematic struggle that literary study has had with the question of evaluation: What makes good literature? I argue that literary studies should own up to this tension and recognize a distinction between ethical criticism, which is explicitly concerned with values, and naturalist criticism, which sidesteps questions of value in favor of understanding how literature works in the mind and in culture. I then argue that the primary relationship between CL and NLP and literary studies should be through naturalist criticism. I conclude by discussing the relative roles of CL and NLP in a large-scale and long-term investigation of romantic love.
Language scientists in Nijmegen have been showing off their artistic side, capturing their research in photography. Head over to Taal in Beeld for a look at the entries – some of them are really stunning.
When looking at the image, it’s tempting to try and find some correlations that look significant and imagine a causal story. However, the text on the screen (taken from artist Nathan Coley’s work “There will be no miracles here“) reminds us that, while we’d like to believe that anyone could make a chance discovery that explains how language works, we must remain rational and keep in mind the bigger picture.
Given this blog’s link with Chen’s study (see Sean’s RT posts here and here), and that Sean and I recently had our own paper published on the topic of these correlational studies, I thought I’d share some of my own thoughts in regards to this video. First up, the video provides some excellent animation, and it does a reasonable job at distilling the core argument of Chen’s paper. However, I do have some concerns, namely the conclusion presented in the video that “even seemingly insignificant features of our language can have a massive impact on our health, our national prosperity and the very way we live and die“.
This is stated far too strongly. After all, the study is only correlational in nature, and there are no experiments supporting this claim. Also, the video makes no mention of the various critiques that have popped up around the web by professional linguists, such as this excellent post by Osten Dahl. Of course, we could hand wave away these critiques, and argue it’s just a fun video. But I worry these popular renditions often lend significant media weight to dubious and unsubstantiated claims, with the potential to influence social policy. Still, we can’t completely blame the video. There’s somewhat of an academic smokescreen at work in the way Chen writes up the paper — it reads as if he had a particular hypothesis, and then tested this using an available dataset. I’m not 100% sure this is the whole story. I wouldn’t be too surprised to hear the initial finding was discovered, rather than actively sought out in a strict hypothesis-testing sense. This is all conjecture on my part, and I could be completely wrong here, but it does seem like Chen was fishing for correlations: you throw out your line into a large sea of data, find a particularly strong association, and then proceed to attach an hypothesis to it. Such practices are exactly the type of problem Sean and I were warning against in our paper. And as Geoff Pullum pointed out: Chen’s causal intuition could easily have been reversed and presented in an equally compelling fashion. It just happened to be the case that the correlation fell in one particular direction.
Besides the numerous theoretical and methodological critiques of the paper, the simple fact of the matter is that Chen’s work is being presented as if it’s demonstrated a causal relation. Let’s be clear about this: he hasn’t even got close to making that point. All he’s found is a strong correlation. So far, the best we can say is that we’re at the hypothesis-generating stage, with the general hypothesis being that differences in grammatical marking of the future influence future-oriented behaviours. Now, if we are to test this hypothesis, then experimental work is going to be needed. I doubt this will be too difficult to do given the large literature into delayed gratification. One useful approach might be found in the Stanford Marshmallow Experiment:
Here, you could control for a whole host of factors, whilst seeing if delayed gratification varied according to the language of particular groups. Surely Chen would expect there to be differences between those populations with strong-FTR languages and those with weak-FTR languages? Also, I wouldn’t be too surprised if we discovered that marshmallow consumption is linked to a propensity to save as well as road traffic accidents, acacia trees and campfires. In short: Marshmallows are the social science equivalent of the Higgs Boson. They’ll unify everything.
Could the Higgsmallow unify all of social science?
Yesterday I put up a post (A Note on Memes and Historical Linguistics) in which I argued that, when historical linguists chart relationships between things they call “languages”, what they’re actually charting is mostly relationships among phonological systems. Though they talk about languages, as we ordinarily use the term, that’s not what they actually look at. In particular, they ignore horizontal transfer of words and concepts between languages.
Consider the English language, which is classified as a Germanic language. As such, it is different from French, which is a Romance language, though of course both Romance and Germanic languages are Indo-European. However, in the 11th Century CE the Norman French invaded Britain and they stuck around, profoundly influencing language and culture in Britain, especially the part that’s come to be known as England. Because of their focus on phonology, historical linguists don’t register this event and its consequences. The considerable French influence on English simply doesn’t count because it affected the vocabulary, but not the phonology.
Well, the historical linguists aren’t the only ones who have a peculiar view of their subject matter. That kind of peculiar vision is widespread.
Let’s take a look at a passage from Sydney Lamb’s Pathways of the Brain (John Benjamins 1999). He begins by talking about Roman Jakobson, one of the great linguists of the previous century:
Born in Russia, he lived in Czechoslovakia and Sweden before coming to the United States, where he became a professor of Slavic Linguistics at Harvard. Using the term language in a way it is commonly used (but which gets in the way of a proper understanding of the situation), we could say that he spoke six languages quite fluently: Russian, Czech, German, English, Swedish, and French, and he had varying amounts of skill in a number of others. But each of them except Russian was spoken with a thick accent. It was said of him that, “He speaks six languages, all of them in Russian”. This phenomenon, quite common except in that most multilinguals don’t control as many ‘languages’, actually provides excellent evidence in support of the conclusion that from a cognitive point of view, the ‘language’ is not a unit at all.
Think about that. “Language” is a noun, nouns are said to represent persons, places, or things – as I recall from some classroom long ago and far away. Language isn’t a person or a place, so it must be a thing. And the generic thing, if it makes any sense at all to talk of such, is a self-contained ‘substance’ (to borrow a word from philosophy), demarcated from the rest of the world. It is, well, it’s a thing, like a ball, you can grab it in your metaphorical hand and turn it around as you inspect it. Continue reading “What’s a Language? Evidence from the Brain”
When I began my most recent series of posts on memes, I did so because I wanted to think specifically about language: Does it make sense to treat words as memes? That question arose for a variety of reasons.
In the first place, if you are going to think about culture as an evolutionary phenomenon, language automatically looms large as so very much of culture depends on or is associated with language. And language consists of words, among other things. Further, historical linguistics is a well-developed discipline. We know a lot about how languages have changed over time, and change over time is what evolution is about.
However, words have meanings. And word meanings are rather fuzzy things, subject to dispute and to change that is independent of the word-form itself. Did I really want to treat word meanings as memes? That seemed rather iffy. But if I don’t treat word meanings as memetic, then what happens to language?
But THAT’s not quite how I put it going into that series of posts. Of course, I’ve known for a long time that words have forms and meanings. I don’t know whether it was my freshman year or my sophomore year that I read Roland Barthe’s Elements of Semiology (English translation 1967). That gave me Saussure’s trilogy of sign, signifier, and signified, the last of which seemed rather mysterious: “the signified is not ‘a thing’ but a mental representation of the ‘thing’.” Getting comfortable with that distinction, between the thing and the concept of the thing, that took time and effort.
That’s an aside. Suffice to say, I got comfortable with that distinction. The distinction between signifier and signified was much easier.
And yet that distinction was not uppermost in my mind when I thought of language and cultural evolution. When I thought of memes. When I approached this series of essays, though some papers by Daniel Dennett, I thought of words they same way Dennett did, the whole kit and caboodle had to be a meme. It was the sign that’s the meme.
That’s not how I ended up, of course. That ending took me a bit by surprise. Coming down that home stretch I was getting worried. It appeared to me that I was faced with two different classes of memes: couplers and the other one. What I did then was to divide the other one into two classes: targets and designators. And to do that I had to call on that thing I’ve known for decades and split the word in two: signifier and signified. It’s only the signifier that’s memetic. Signifiers are memes, but not signifieds.
It took me a couple of months to work that out, and I’d known it all along.
Sorta’.
What does that have to do with historical linguistics? Historical linguistics is based mostly on the study of relationships among signifiers, that is, relationships among the memetic elements of languages. Which makes sense, of course.
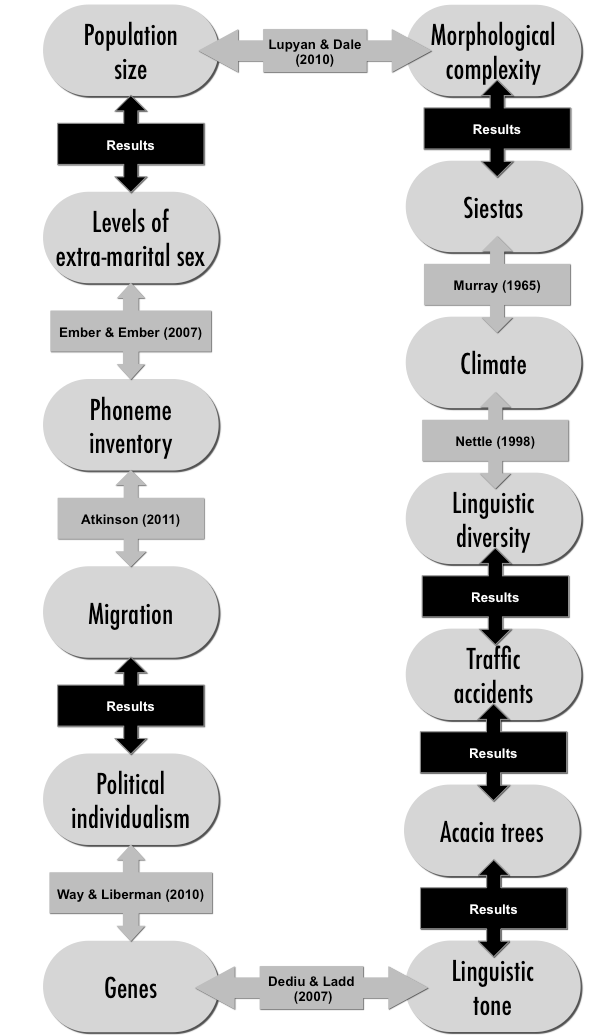
James and I have a new paper out in PLOS ONE where we demonstrate a whole host of unexpected correlations between cultural features. These include acacia trees and linguistic tone, morphology and siestas, and traffic accidents and linguistic diversity.
We hope it will be a touchstone for discussing the problems with analysing cross-cultural statistics, and a warning not to take all correlations at face value. It’s becoming increasingly important to understand these issues, both for researchers as more data becomes available, and for the general public as they read more about these kinds of study in the media (e.g. recent coverage in National Geographic, the BBC and TED). But why are the public fascinated with these findings? Here’s my guess:
People are always intrigued by stories of scientific discovery. From Mary Anning‘s discovery of a fossilised ichthyosaur when she was just 12 years old, to Fleming’s accidental production of penicilin to Newton’s apple, it’s tempting to think that anyone could trip over a major breakthrough that is out there just waiting to be found. This is perhaps why there has been so much media interest recently in studies which show surprising statistical links between cultural features such as chocolate consumption and Nobel laureates, future tense and economic decisions, linguistic gender and power or geography and phoneme inventory.
Everett recalled being shocked by his discovery. “I remember stepping out from my desk and saying, ‘Okay, this is kind of crazy,'” he said. “My first question was, How had we not noticed this?”
That is, we live in an age when there is more data available than ever before, it’s more widely available and there are better tools to do analyses. Anyone with an ordinary laptop and access to the internet could make these discoveries. Indeed, we’ve uncovered many unexpected correlations at Replicated Typo. However, just as Anning’s discoveries were made as the theory of biological evolution was still developing, the ability to detect correlations in cultural features is outstripping the understanding of how to assess these findings. Early reconstructions of fossils included a lot of errors, some of which have been difficult to redress in the public’s mind. Without a good understanding of cultural evolution, similar mistakes might be made during the current race to find statistical links in our field.
An early reconstruction of Megalosaurus by Richard Owen, based on limited evidence and theory, compared with the modern reconstruction source
Everyone knows that correlation does not imply causation, but there are other problems inherent in studies of cultural features. One problem that is often discounted in these kinds of study is the historical relationship between cultures. Cultural features tend to diffuse in bundles, inflating the apparent links between causally unrelated features. This means that it’s not a good idea to count cultures or languages as independent from each other. Here’s an example: Suppose we look at a group of highschool students and wonder whether the colour of their t-shirts correlates with the kind of food they bring for lunch. We survey 10 children, and see that 5 wear red t-shirts and eat peanut-butter sandwiches. This appears to be strong evidence for a link, but then we see that these 5 pupils come from the same family. There’s now a better explanation for the trend – the children from the same family tend to have the same choice of clothes and are given the same lunch by their parents. The same problem exists for languages. Languages in the same historical families, like English and German, tend to have inherited the same bundles of linguistic features. For this reason, it can be quite complicated to work out whether there really are causal links between cultural properties.
Our paper tries to demonstrate the importance of controlling for this problem by pointing out a chain of statistically significant links, some of which are unlikely to be causal. The diagram below shows the links, those marked with ‘Results’ are links that we’ve discovered and demonstrate in the paper.
For instance, linguistic diversity is correlated with the number of traffic accidents in a country, even controlling for population size, population density, GDP and latitude. While there may be hidden causes, such as state cohesion, it would be a mistake to take this as evidence that linguistic diversity caused traffic accidents.
In the paper we suggest that correlation studies should demonstrate at least two things:
That the hypothesised correlation is stronger than correlations between similar cultural features that are not expected to be linked.
That the hypothesised correlation is robust against controlling for cultural descent.
We discuss some methods for achieving this, and demonstrate that they can debunk the spurious correlations that we discover in the first section. Many of these methods are straightforward and can be done quickly, so there’s no excuse for avoiding them.
As well as careful statistical controls, correlation studies can also be assessed based on whether they are motivated by prior theory or not. For example, Lupyan & Dale’s (2010) demonstration of a correlation between population size and morphological complexity was motivated by a long line of research on languages in contact. However, both kinds of discovery can be useful if they are seen in the context of a wider scientific method. We argue that correlation studies should be viewed as explorations of data, and as a sort of feasibility study for further, experimental, research. For example, the chance discovery of a link between genes and tone by Dediu & Ladd was not only statistically well controlled, but was used as the inspiration for more detailed laboratory experiments, rather than being seen as proof in itself.
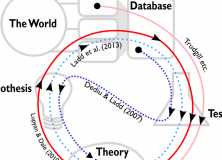
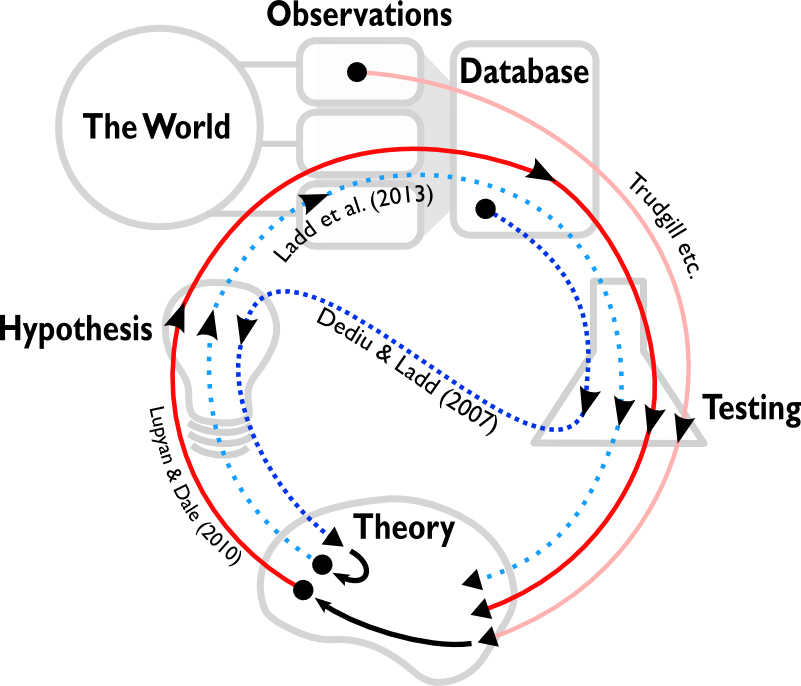
The scientific processes of different nomothetic studies. Observations are drawn from the world, either as idiographic studies or experiments. These observations can be compiled into large-scale cross-cultural databases. Scientific elements include theory, hypotheses and testing. Trajectories indicate the process of different studies. Processes start at a dot and continue in the direction indicated by the arrows. The ideal trajectory is the following: A theory generates a hypothesis. The hypothesis suggests data to collect, which is then tested. The results of the test feed back into the theory. Lupyan & Dale (2010) follow this trajectory, although they take their data from a large-scale cross-cultural database. Lupyan & Dale’s theory was generated by previous testing of (small-scale) observations by Trudgill and others. The trajectory of Dediu & Ladd’s study differs in two ways. First, the trajectory starts with large-scale cross-cultural data rather than small-scale observations. Secondly, the testing generates the hypothesis, which suggests a theory. However, Ladd et al. (2013) use this theory to motivate a hypothesis which is tested on experimental data. Since developing theories from small-scale observations takes time and effort, Dediu & Ladd’s study has effectively jump-started the conventional scientific process.
Coming across statistical patterns by chance has always been part of the scientific process. However, with culture, it’s much more difficult to intuitively distinguish real patterns from noise or historical influence. Correlations between unexpected features will continue to be exciting, but researchers should apply the right controls and see the studies as motivational rather than direct tests of hypotheses.
Roberts, S. & Winters, J. (2013). Linguistic Diversity and Traffic Accidents: Lessons from Statistical Studies of Cultural Traits. PLOS ONE, 8 (8) e70902 : doi:10.1371/journal.pone.0070902
Though it has roots in 19th Century mathematics, the idea of recursion owes most of its development 20th Century work in mathematics, logic, and computing, where it has become one of the most fruitful ideas in modern–or is it post-modern?–thought. By making it central to his work in language syntax, Chomsky introduced recursion into discussions about the fundamental architecture of the human mind. The question of whether or not syntax is recursive has been important, and controversial, ever science.
My teacher, the late David Hays, was a computational linguist and had somewhat different ideas about recursion. When I say that he was a computational linguist I mean that he devoted a great deal of time and intellectual effort to the problem, first of machine translation, and then more generally to using computer programs to simulate language processing. Back in those days computers were physically large, but computationally weak in comparison with today’s laptops and smart phones. Recursive syntax required more computational resources (memory space and CPU cycles per unit of time) than were available. Transformational grammars were computationally difficult.
Hays was of the view that recursion was a property of the human mind as a whole, but not necessarily of the syntactic component of language. In particular, building on Roman Jakonson’s notion of language’s metalingual function, he developed an account of metalingual definition for abstract concepts that allowed for the recursive nesting of definitions within one another (Cognitive networks and abstract terminology, Journal of Clinical Computing, 3(2):110-118, 1973).
Given that Hays was my teacher, it will come as no surprise that I favor his view of the matter. But I will also note that I had become skeptical about Chomskian linguistics even before I came to study with Hays, though I had started out as a fan.
This is the final post in my current series on memes, cultural evolution, and the thought of Daniel Dennett. You can download a PDF of the whole series HERE. The abstract and introduction are below.
* * * * *
Abstract: Philosopher Dan Dennett’s conception of the active meme, moving about from brain to brain, is physically impossible and conceptually empty. It amounts to cultural preformationism. As the cultural analogue to genes, memes are best characterized as the culturally active properties of things, events, and processes in the external world. Memes are physically embodied in a substrate. The cultural analogue to the phenotype can be called an ideotype; ideotypes are mental entities existing in the minds of individual humans. Memes serve as targets for designing and fabricating artifacts, as couplers to synchronize and coordinate human interaction, and as designators (Saussaurian signifiers). Cultural change is driven by the movement of memes between populations with significantly different cultural practices understood through different populations of ideotypes.
* * * * *
Introduction: Taming the Wild Meme
These notes contain my most recent thinking on cultural evolution, an interest that goes back to my dissertation days in the 1970s at the State University of New York at Buffalo. My dissertation, Cognitive Science and Literary Theory (1978), included a chapter on narrative, “From Ape to Essence and the Evolution of Tales,” (subsequently published as “The Evolution of Narrative and the Self”). But that early work didn’t focus on the process of cultural evolution. Rather, it was about the unfolding of ever more sophisticated cultural forms–an interest I shared with my teacher, the late David G. Hays.
My current line of investigation is very much about process, the standard evolutionary process of random variation and selective retention as applied to cultural forms, rather than living forms. I began that work in the mid-1990s and took my cue from Hays, as I explain in the section below, “What’s a meme? Where I got my conception”. At the end of the decade I had drafted a book on music, Beethoven’s Anvil: Music in Mind and Culture (Basic 2001), in which I arrived at pretty much my current conception, but only with respect to music: music memes are the culturally active properties musical sound.
I didn’t generalize the argument to language until I prepared a series of posts conceived as background to a (rather long and detailed) post I wrote for the National Humanities Institute in 2010: Cultural Evolution: A Vehicle for Cooperative Interaction Between the Sciences and the Humanities (PDF HERE). But I didn’t actually advance this conception in that post. Rather, I tucked it into an extensive series of background posts that I posted at New Savanna prior to posting my main article. That’s where, using the emic/etic distinction, I first advanced the completely general idea that memes are observable properties of objects and things that are culturally active. I’ve collected that series of posts into a single downloadable PDF: The Evolution of Human Culture: Some Notes Prepared for the National Humanities Center, Version 2.
But I still had doubts about that position. Though the last three of those background posts were about language, I still had reservations. The problem was meaning: If that conception was correct, then word meanings could not possibly be memetic. Did I really want to argue that?
The upshot of this current series of notes is that, yes, I really want to argue it. And I have done at some length while using several articles by the philosopher Daniel Dennett as my foil. For the most part I focus on figuring out what kinds of entities play the role of memes, but toward the end, “Cultural Evolution, So What?”, I have a few remarks about long-term dynamics, that is, about cultural change. Continue reading “Cultural Evolution, Memes, and the Trouble with Dan Dennett”

 Professor Russell Gray (University of Auckland, New Zealand) will present his work on the evolution of language, culture and cognition at the annual Nijmegen Lectures in January 2014.
Professor Russell Gray (University of Auckland, New Zealand) will present his work on the evolution of language, culture and cognition at the annual Nijmegen Lectures in January 2014.










{kind=link}