At next year’s International Congress of Phonetic Sciences in Glasgow there will be a special interest group on the Evolution of our phonetic capabilities. It will focus on the interaction between biological and cultural evolution and encourages work from different modalities too. The call for papers is below:
In recent years, there has been a resurgence in research in the evolution of language and speech. New techniques in computational and mathematical modelling, experimental paradigms, brain and vocal tract imaging, corpus analysis and animal studies, as well as new archeological evidence, have allowed us to address questions relevant to the evolution of our phonetic capabilities.
This workshop requests contributions from researchers which address the emergence of our phonetic capabilities. We are interested in empirical evidence from models and experiments which explore evolutionary pressures causing the emergence of our phonetic capabilities, both in biological and cultural evolution, and the consequences biological constraints will have on processes of cultural evolution and vice versa. Contributions are welcome to cover not only the evolution of our physical ability to produce structured signals in different modalities, but also cognitive or functional processes that have a bearing on the emergence of phonemic inventories. We are also interested in contributions which look at the interaction between the two areas mentioned above which are often dealt with separately in the field, that is the interaction between physical constraints imposed by a linguistic modality, and cognitive constraints born from learning biases and functional factors, and the consequences this interaction will have on emerging linguistic systems and inventories.
Contributions can be sent as an attachment to hannah@ai.vub.ac.be by 16th February 2015
The deadline is obviously quite far away, but feel free to use the same email address above to ask any questions about suitability of possible submissions or anything else.
This year saw the 10th instalment of the EvoLang Conference, and it was also the 15th anniversary of Luc Steels’ Talking Heads Experiment (brief review here). In celebration, the Evolutionary Linguistics Association organised a birthday party in Replugged (Vienna). The party not only featured some excellent tuneage by replicated typo’s very own Sean Roberts along with Bill Thompson, Tessa Verhoef and me, but it also featured, very aptly, a Talking Heads tribute band headed by none other than Luc Steels himself! For those of you who were there (or weren’t there), you can now relive (or see for the first time) the experience through YouTube (extra points for spotting your favourite evolutionary linguists dancing their little socks off):
Oh wait, I’m not a guest anymore. Thanks to James for inviting me to become a regular contributor to Replicated Typo. I hope I will have to say some interesting things about the evoution of language, cognition, and culture, and I promise that I’ll try to keep my next posts a bit shorter than the guest post two weeks ago.
Today I’d like to pick up on an ongoing discussion over at Language Log. In a series of blog posts in early 2012, Mark Liberman has taken issue with the so-called “QWERTY effect”. The QWERTY effect seems like an ideal topic for my first regular post as it is tightly connected to some key topics of Replicated Typo: Cultural evolution, the cognitive basis of language, and, potentially, spurious correlations. In addition, Liberman’s coverage of the QWERTY effect has spawned an interesting discussion about research blogging (cf. Littauer et al. 2014).
But what is the QWERTY effect, actually? According to Kyle Jasmin and Daniel Casasanto (Jasmin & Casasanto 2012), the written form of words can influence their meaning, more particularly, their emotional valence. The idea, in a nutshell, is this: Words that contain more characters from the right-hand side of the QWERTY keyboard tend to “acquire more positive valences” (Jasmin & Casasanto 2012). Casasanto and his colleagues tested this hypothesis with a variety of corpus analyses and valence rating tasks.
Whenever I tell fellow linguists who haven’t heard of the QWERTY effect yet about these studies, their reactions are quite predictable, ranging from “WHAT?!?” to “asdf“. But unlike other commentors, I don’t want to reject the idea that a QWERTY effect exists out of hand. Indeed, there is abundant evidence that “right” is commonly associated with “good”. In his earlier papers, Casasanto provides quite convincing experimental evidence for the bodily basis of the cross-linguistically well-attested metaphors RIGHT IS GOOD and LEFT IS BAD (e.g. Casasanto 2009). In addition, it is fairly obvious that at the end of the 20th century, computer keyboards started to play an increasingly important role in our lives. More and more people have full size keyboards somewhere in their home. Also, it seems legitimate to assume that in a highly literate society, written representations of words form an important part of our linguistic knowledge. Given these factors, the QWERTY effect is not such an outrageous idea. However, measuring it by determining the “Right-Side Advantage” of words in corpora is highly problematic since a variety of potential confounding factors are not taken into account.
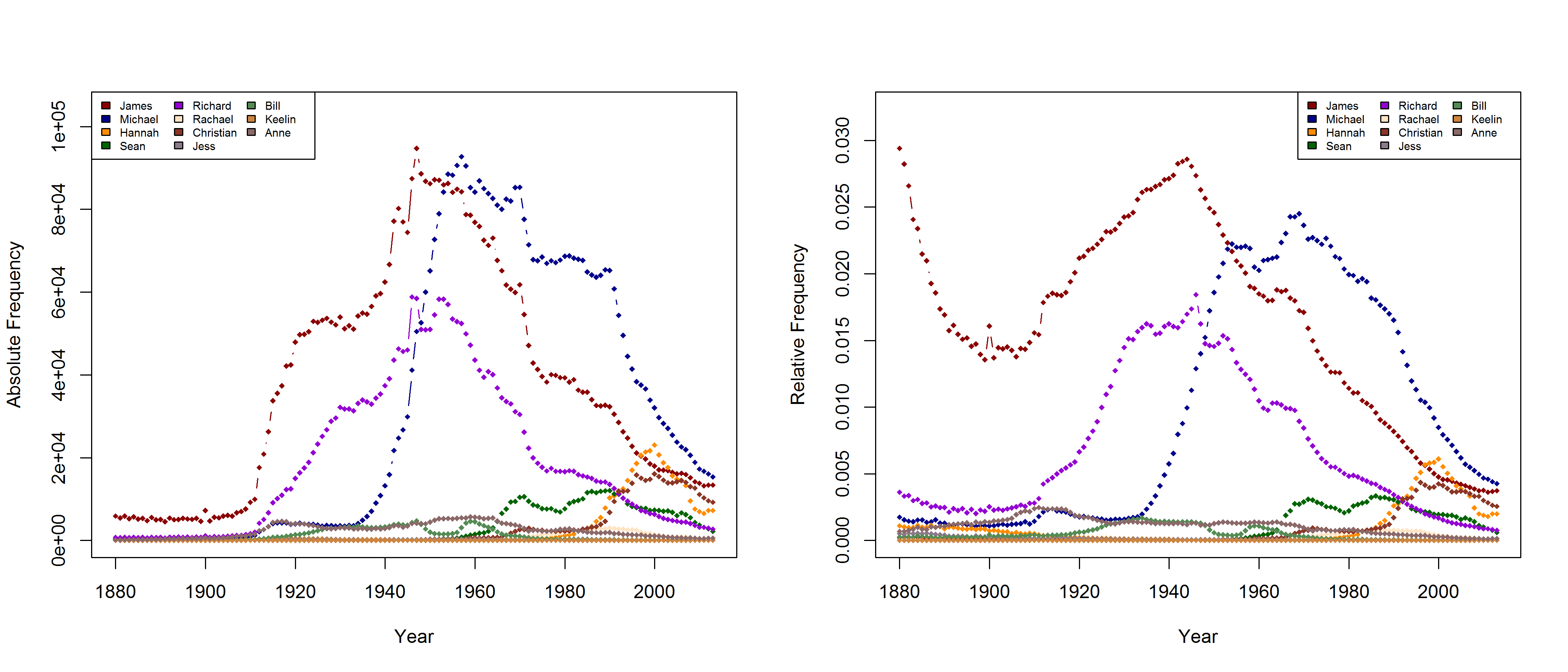
Finding the Right Name(s)
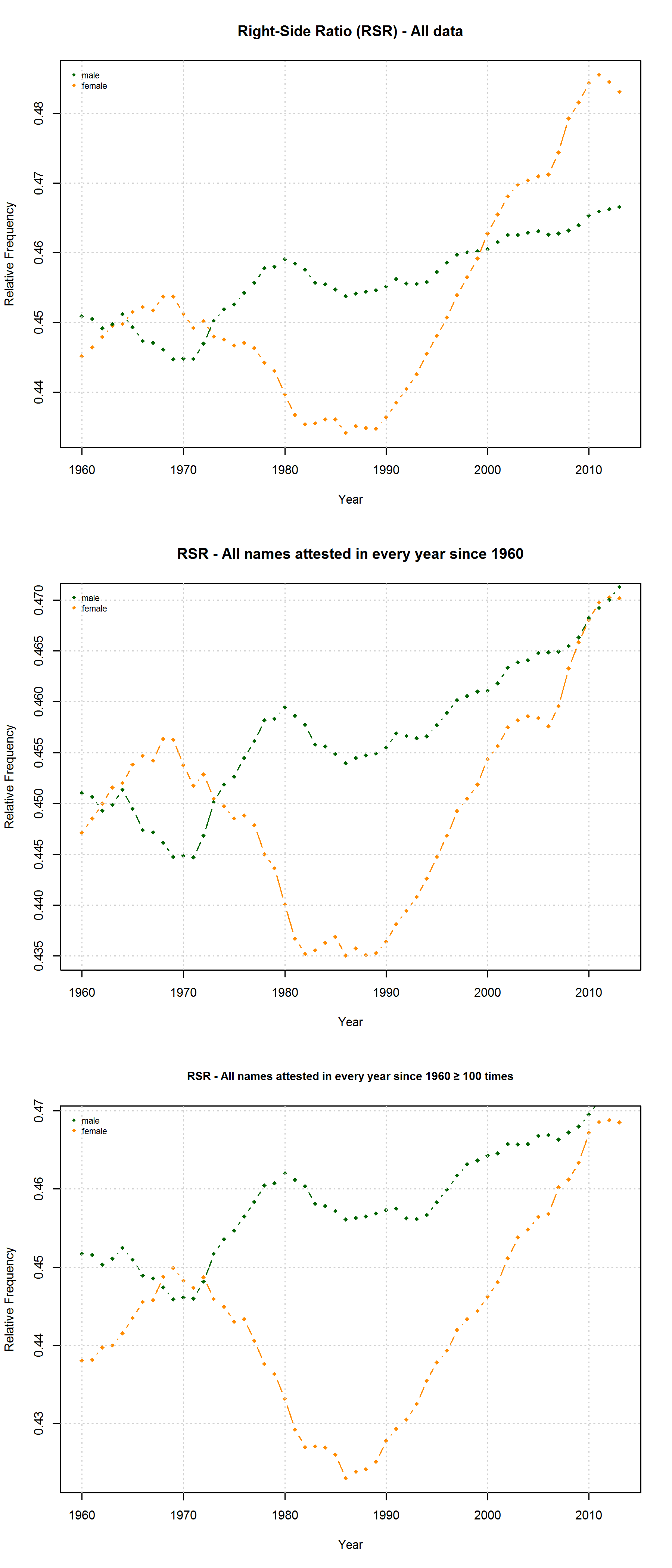
Frequencies of some (almost) randomly selected names in the USA.
In a new CogSci paper, Casasanto, Jasmin, Geoffrey Brookshire, and Tom Gijssels present five new experiments to support the QWERTY hypothesis. Since I am based at a department with a strong focus on onomastics, I found their investigation of baby names particularly interesting. Drawing on data from the US Social Security Administration website, they analyze all names that have been given to more than 100 babys in every year from 1960 to 2012. To determine the effect of keyboard position, they use a measure they call “Right Side Adventage” (RSA): [(#right-side letters)-(#left-side letters)]. They find that
“that the mean RSA has increased since the popularization of the QWERTY keyboard, as indicated by a correlation between the year and average RSA in that year (1960–2012, r = .78, df = 51, p =8.6 × 10-12“
In addition,
“Names invented after 1990 (n = 38,746) use more letters from the right side of the keyboard than names in use before 1990 (n = 43,429; 1960–1990 mean RSA = -0.79; 1991–2012 mean RSA = -0.27, t(81277.66) = 33.3, p < 2.2 × 10-16 […]). This difference remained significant when length was controlled by dividing each name’s RSA by the number of letters in the name (t(81648.1) = 32.0, p < 2.2 × 10-16)”
Mark Liberman has already pointed to some problematic aspects of this analysis (but see also Casasanto et al.’s reply). They do not justify why they choose the timeframe of 1960-2012 (although data are available from 1880 onwards), nor do they explain why they only include names given to at least 100 children in each year. Liberman shows that the results look quite different if all available data are taken into account – although, admittedly, an increase in right-side characters from 1990 onwards can still be detected. In their response, Casasanto et al. try to clarify some of these issues. They present an analysis of all names back to 1880 (well, not all names, but all names attested in every year since 1880), and they explain:
“In our longitudinal analysis we only considered names that had been given to more than 100 children in *every year* between 1960 and 2012. By looking at longitudinal changes in the same group of names, this analysis shows changes in names’ popularity over time. If instead you only look at names that were present in a given year, you are performing a haphazard collection of cross-sectional analyses, since many names come and go. The longitudinal analysis we report compares the popularity of the same names over time.“
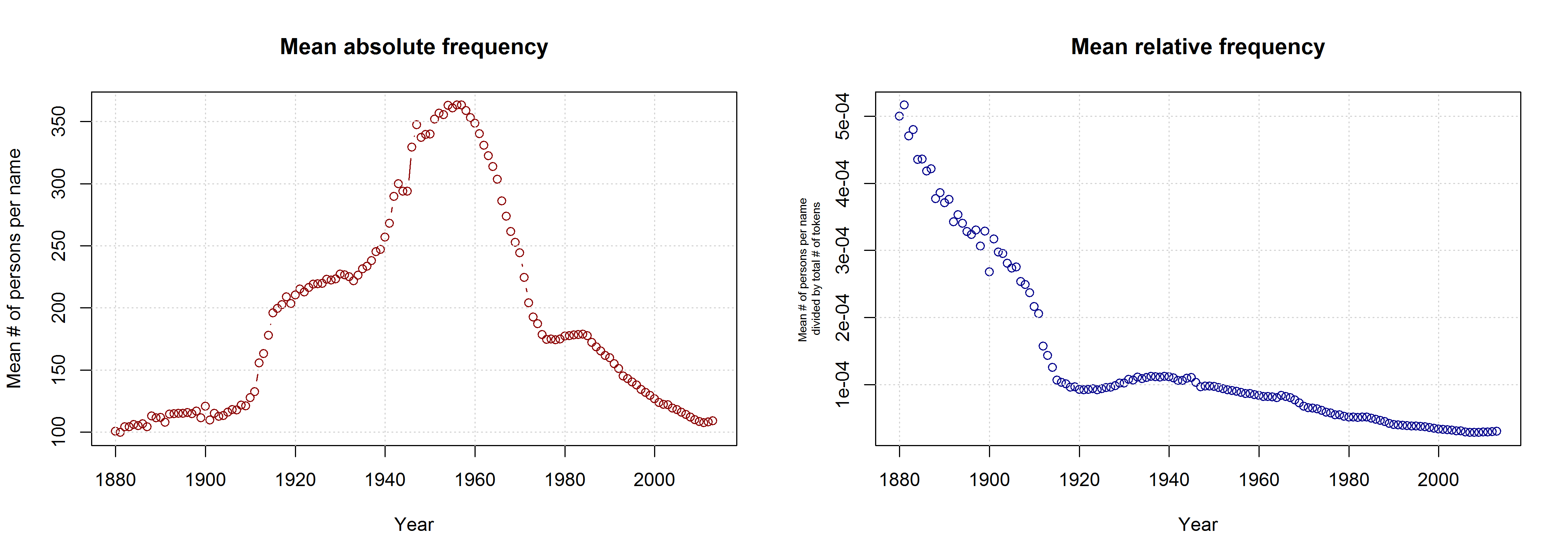
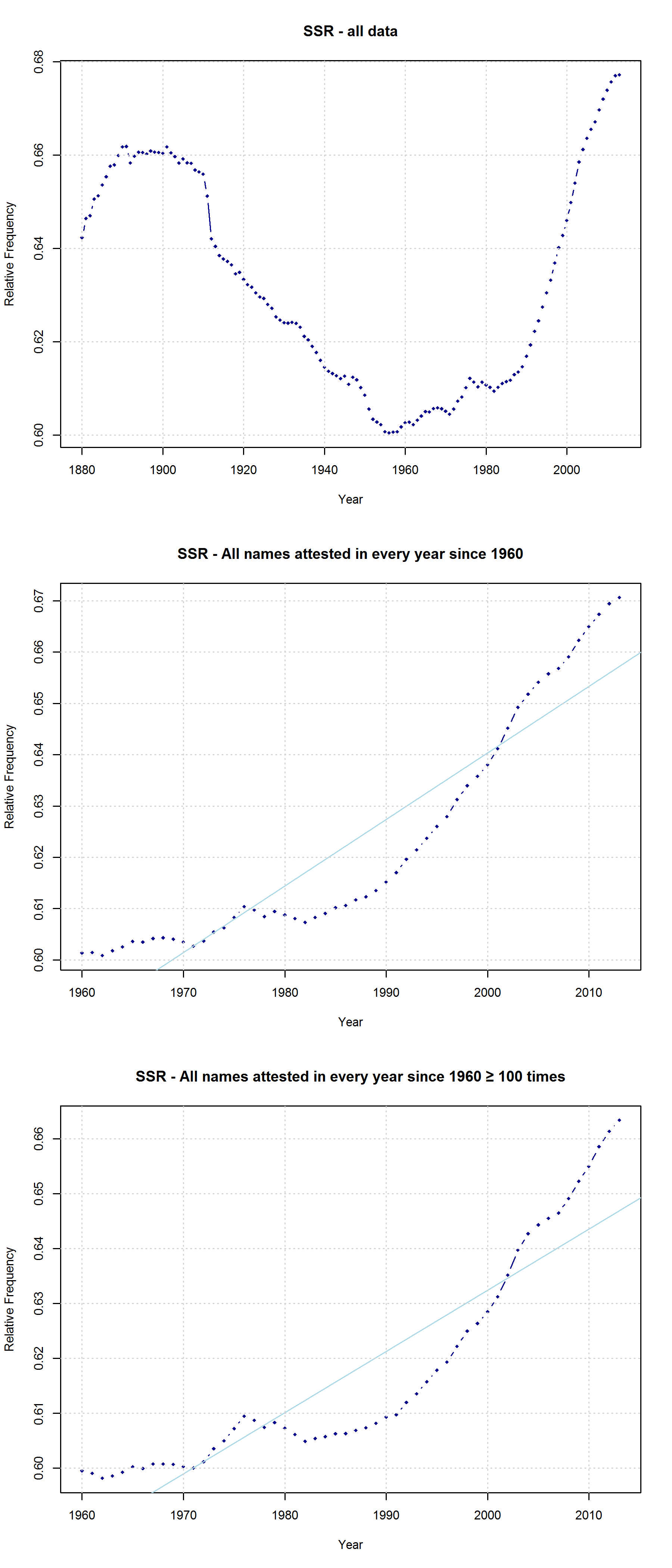
I am not sure what to think of this. On the one hand, this is certainly a methodologically valid approach. On the other hand, I don’t agree that it is necessarily wrong to take all names into account. Given that 3,625 of all name types are attested in every year from 1960 to 2013 and that only 927 of all name types are attested in every year from 1880 to 2013 (the total number of types being 90,979), the vast majority of names is simply not taken into account in Casasanto et al.’s approach. This is all the more problematic given that parents have become increasingly individualistic in naming their children: The mean number of people sharing one and the same name has decreased in absolute terms since the 1960s. If we normalize these data by dividing them by the total number of name tokens in each year, we find that the mean relative frequency of names has continuously decreased over the timespan covered by the SSA data.
Mean frequency of a name (i.e. mean number of people sharing one name) in absolute and relative terms, respectively.
Thus, Casasanto et al. use a sample that might be not very representative of how people name their babies. If the QWERTY effect is a general phenomenon, it should also be found when all available data are taken into account.
As Mark Liberman has already shown, this is indeed the case – although some quite significant ups and downs in the frequency of right-side characters can be detected well before the QWERTY era. But is this rise in frequency from 1990 onwards necessarily due to the spread of QWERTY keyboards – or is there an alternative explanation? Liberman has already pointed to “the popularity of a few names, name-morphemes, or name fragments” as potential factors determining the rise and fall of mean RSA values. In this post, I’d like to take a closer look at one of these potential confounding factors.
Sonorous Sounds and “Soft” Characters
When I saw Casasanto et al.’s data, I was immediately wondering if the change in character distribution could not be explained in terms of phoneme distribution. My PhD advisor, Damaris Nübling, has done some work (see e.g. here [in German]) showing an increasing tendency towards names with a higher proportion of sonorous sounds in Germany. More specifically, she demonstrates that German baby names become more “androgynous” in that male names tend to assume features that used to be characteristic of (German) female names (e.g. hiatus; final full vowel; increase in the overall number of sonorous phonemes). Couldn’t a similar trend be detectable in American baby names?
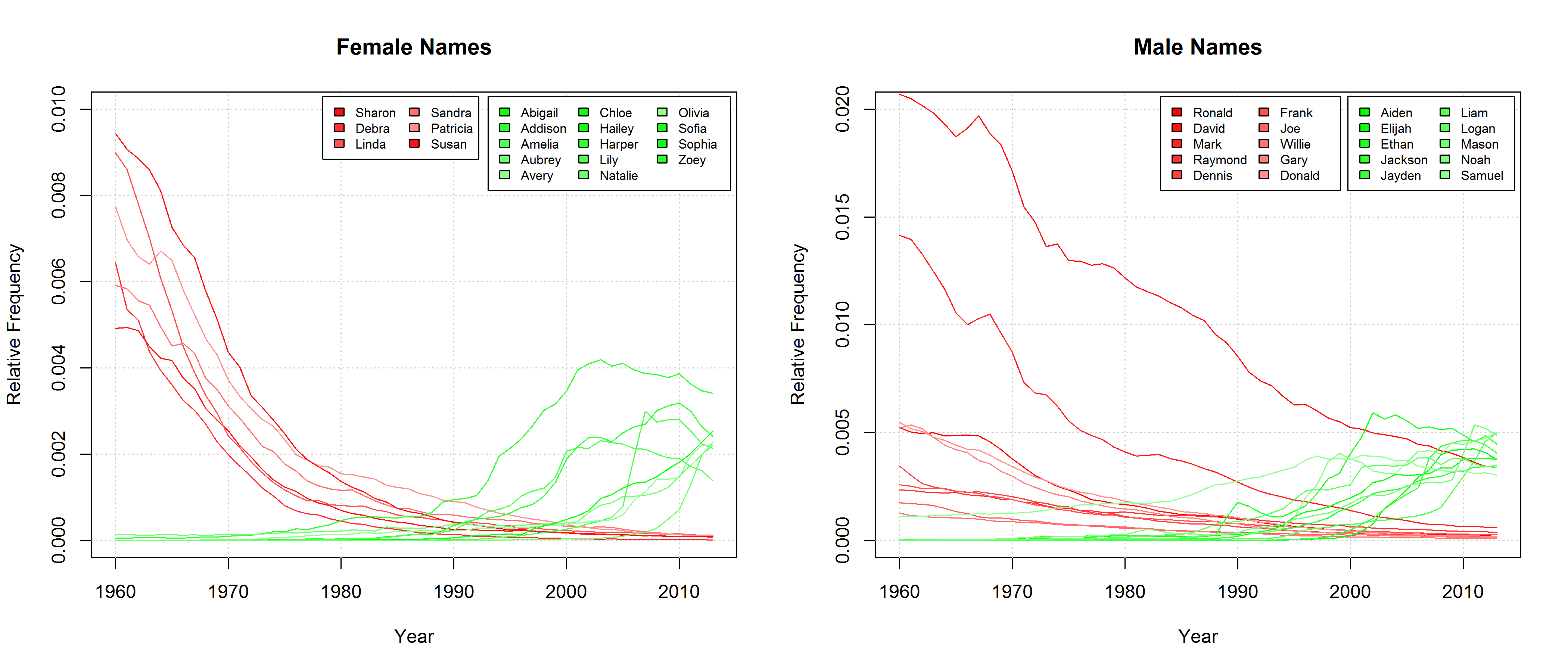
Names showing particularly strong frequency changes among those names that appear among the Top 20 most frequent names at least once between 1960 and 2013.
If we take a cursory glance at those names that can be found among the Top 20 most frequent names of at least one year since 1960 and if we single out those names that experienced a particularly strong increase or decrease in frequency, we find that, indeed, sonorous names seem to become more popular. Those names that gain in popularity are characterized by lots of vowels, diphthongs (Aiden, Jayden, Abigail), hiatus (Liam, Zoey), as well as nasals and liquids (Lily, Liam).
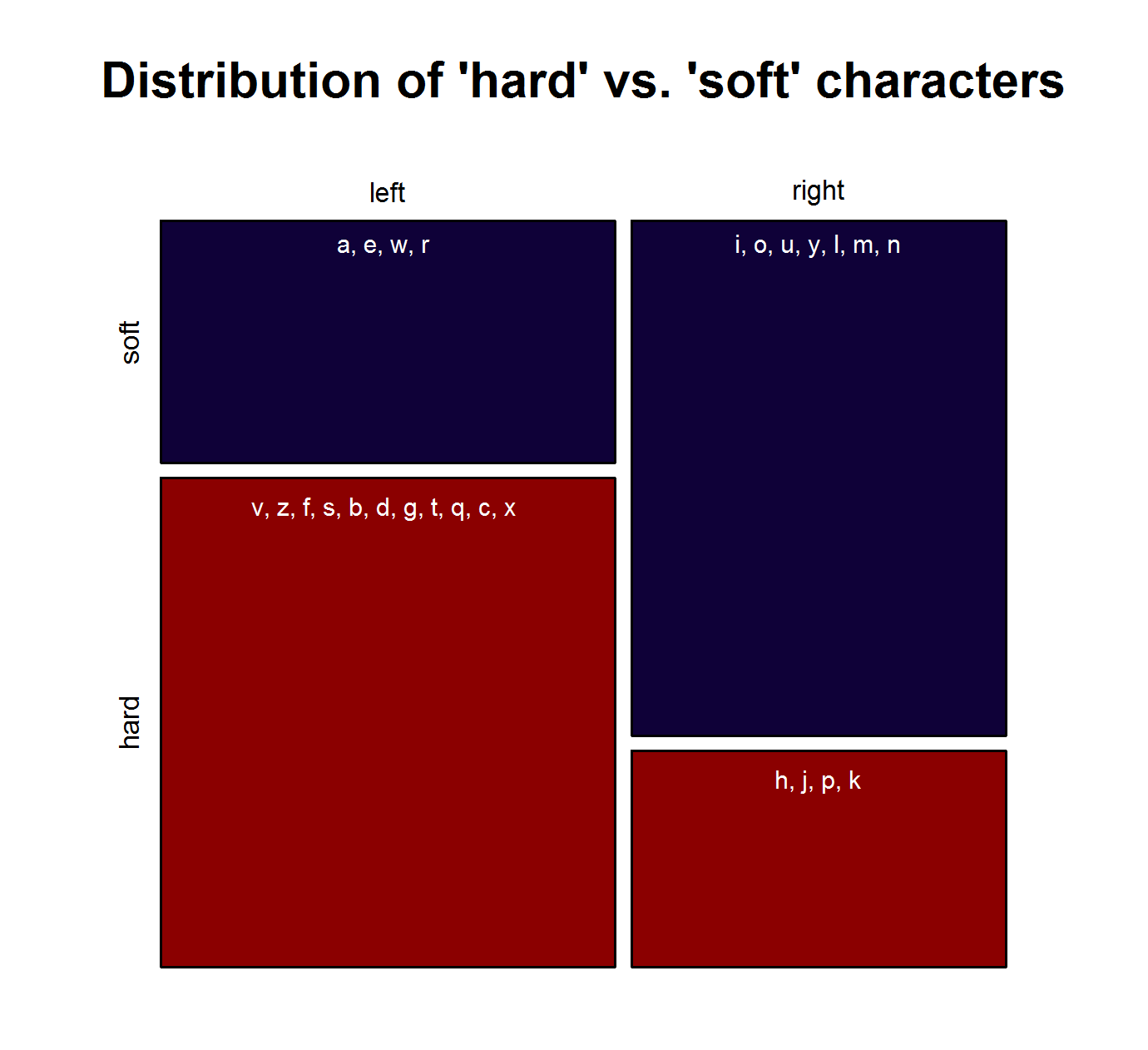
To be sure, these cursory observations are not significant in and of themselves. To test the hypothesis if phonological changes can (partly) account for the QWERTY effect in a bit more detail, I basically split the sonority scale in half. I categorized characters typically representing vowels and sonorants as “soft sound characters” and those typically representing obstruents as “hard sound characters”. This is of course a ridiculously crude distinction entailing some problematic classifications. A more thorough analysis would have to take into account the fact that in many cases, one letter can stand for a variety of different phonemes. But as this is just an exploratory analysis for a blog post, I’ll go with this crude binary distinction. In addition, we can justify this binary categorization with an argument presented above: We can assume that the written representations of words are an important part of the linguistic knowledge of present-day language users. Thus, parents will probably not only be concerned with the question how a name sounds – they will also consider how it looks like in written form. Hence, there might be a preference for characters that prototypically represent “soft sounds”, irrespective of the sounds they actually stand for in a concrete case. But this is highly speculative and would have to be investigated in an entirely different experimental setup (e.g. with a psycholinguistic study using nonce names).
Distribution of “hard sound” vs. “soft sound” characters on the QWERTY keyboard.
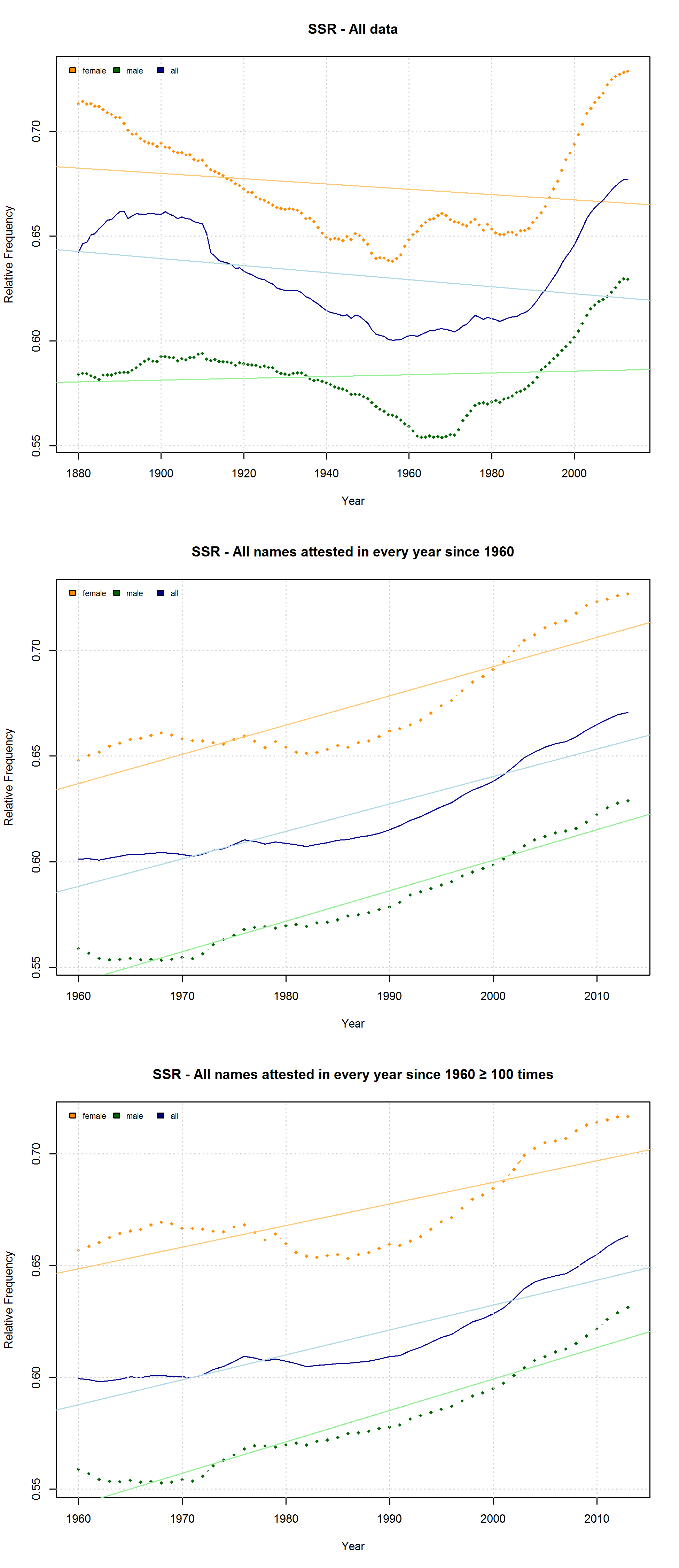
Note that the characters representing “soft sounds” and “hard sounds”, respectively, are distributed unequally over the QWERTY keyboard. Given that most “soft sound characters” are also right-side characters, it is hardly surprising that we cannot only detect an increase in the “Right-Side Advantage” (as well as the “Right-Side Ratio”, see below) of baby names, but also an increase in the mean “Soft Sound Ratio” (SSR – # of soft sound characters / total # of characters). This increase is significant for the time from 1960 to 2013 irrespective of the sample we use: a) all names attested since 1960, b) names attested in every year since 1960, c) names attested in every year since 1960 more than 100 times.
“Soft Sound Ratio” in three different samples: a) All names attested in the SSA data; b) all names attested in every year since 1960; c) all names attested in every year since 1960 at least 100 times.
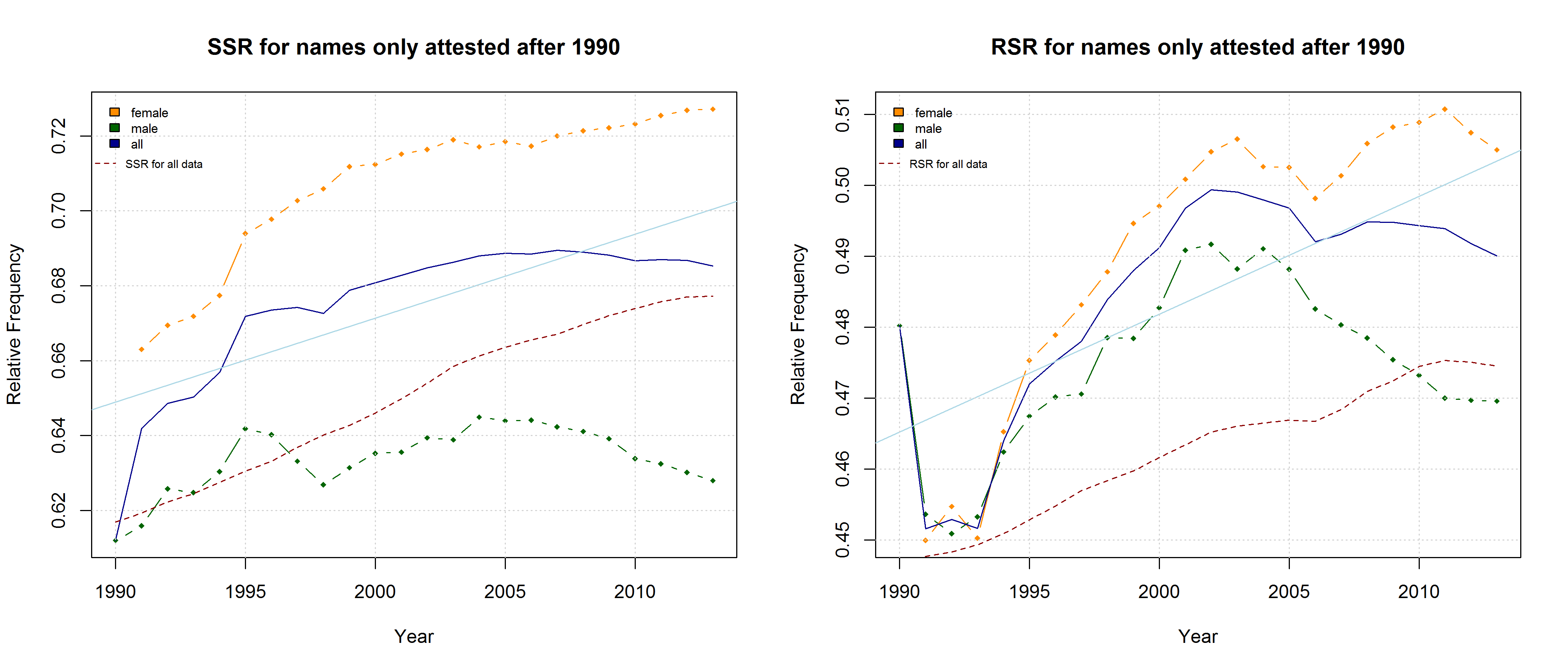
Note that both the “Right-Side Advantage” and the “Soft Sound Ratio” are particularly high in names only attested after 1990. (For the sake of (rough) comparability, I use the relative frequency of right-side characters here, i.e. Right Side Ratio = # of right-side letters / total number of letters.)
“Soft Sound Ratio” and “Right-Side Ratio” for names only attested after 1990.
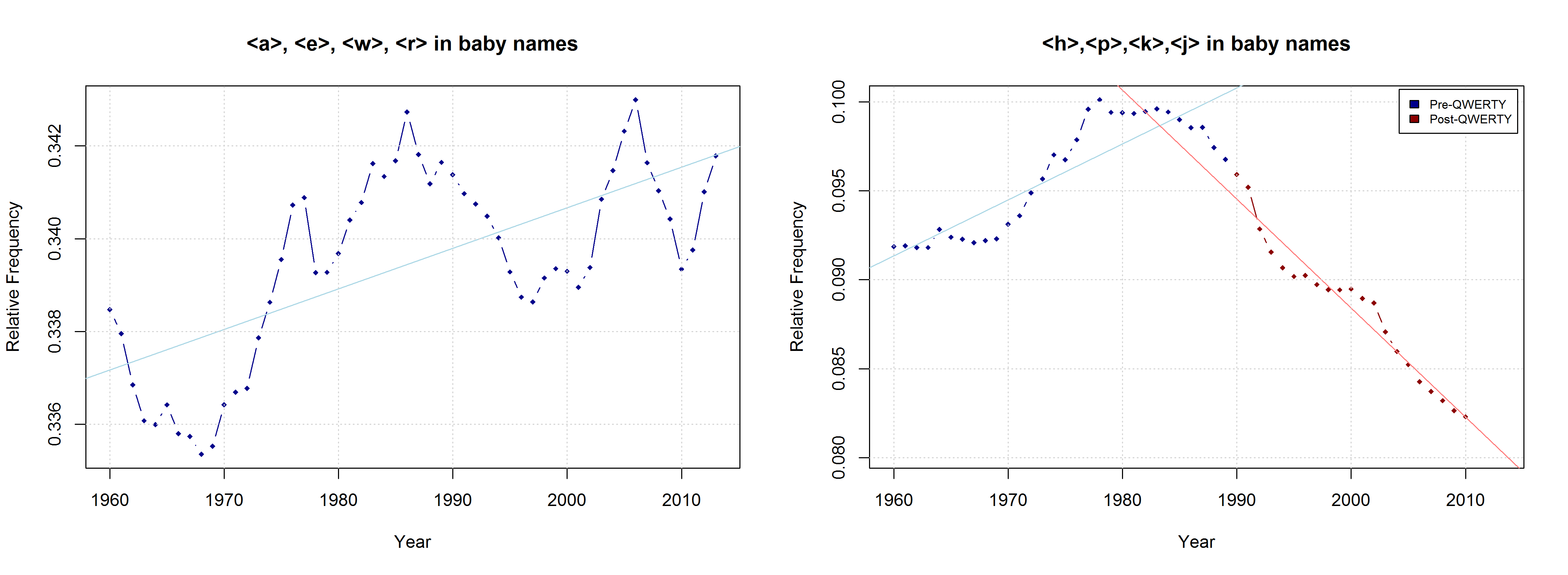
Due to the considerable overlap between right-side and “soft” characters, both the QWERTY Effect and the “Soft Sound” Hypothesis might account for the changes that can be observed in the data. If the QWERTY hypothesis is correct, we should expect an increase for all right-side characters, even those that stand for “hard” sounds. Conversely, we should expect a decrease in the relative frequency of left-side characters, even if they typically represent “soft” sounds. Indeed, the frequency of “Right-Side Hard Characters” does increase – in the time from 1960 to the mid-1980s. In the QWERTY era, by contrast, <h>, <p>, <k>, and <j> suffer a significant decrease in frequency. The frequency of “Left-Side Soft Characters”, by contrast, increases slightly from the late 1960s onwards.
Frequency of left-side “soft” characters and right-side “hard” characters in all baby names attested from 1960 to 2013.
Further potential challenges to the QWERTY Effect and possible alternative experimental setups
The commentors over at Language Log have also been quite creative in coming up with possible alternative explanations and challenging the QWERTY hypothesis by showing that random collections of letters show similarly strong patterns of increase or decrease. Thus, the increase in the frequency of right-side letters in baby names is perhaps equally well, if not better explained by factors independent of character positions on the QWERTY keyboard. Of course, this does not prove that there is no such thing as a QWERTY effect. But as countless cases discussed on Replicated Typo have shown, taking multiple factors into account and considering alternative hypotheses is crucial in the study of cultural evolution. Although the phonological form of words is an obvious candidate as a potential confounding factor, it is not discussed at all in Casasanto et al.’s CogSci paper. However, it is briefly mentioned in Jasmin & Casasanto (2012: 502):
“In any single language, it could happen by chance that words with higher RSAs are more positive, due to sound–valence associations. But despite some commonalities, English, Dutch, and Spanish have different phonological systems and different letter-to-sound mappings.”
While this is certainly true, the sound systems and letter-to-sound mappings of these languages (as well as German and Portugese, which are investigated in the new CogSci paper) are still quite similar in many respects. To rule out the possibility of sound-valence associations, it would be necessary to investigate the phonological makeup of positively vs. negatively connotated words in much more detail.
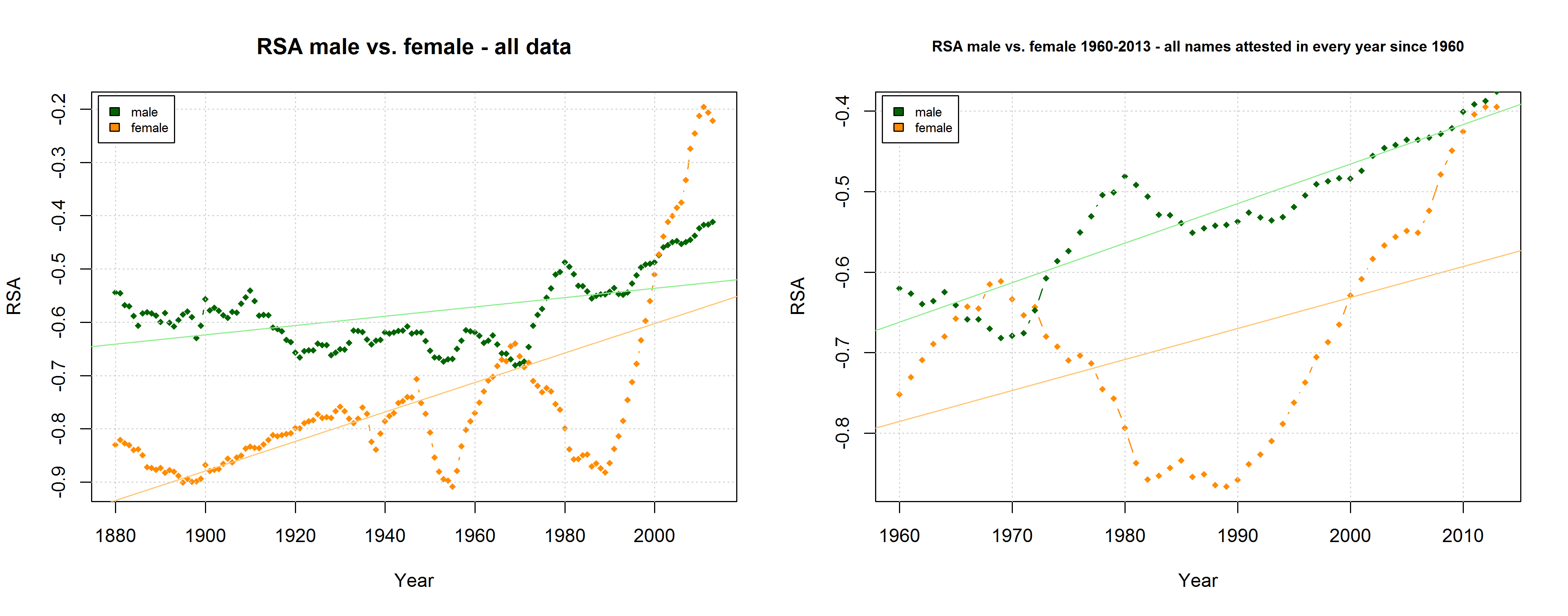
Right-Side Advantage (RSA) for male vs. female names in two different samples (all names attested in the SSA data and all names attested in every year since 1960).
The SSA name lists provide another means to critically examine the QWERTY hypothesis since they differentiate between male and female names. If the QWERTY effect does play a significant role in parents’ name choices, we would expect it to be equally strong for boys names and girls names – or at least approximately so.
Right-Side Ratio for three different samples (all names attested in the SSA lists, all names attested in every year since 1960, all years attested in every year since 1960 at least 100 times).
On the hypothesis that other factors such as trend names play a much more important role, by contrast, differences between the developments of male vs. female names are to be expected. Indeed, the data reveal some differences between the RSA / RSR development of boys vs. girls names. At the same time, however, these differences show that the “Soft Sound Hypothesis” can only partly account for the QWERTY Effect since the “Soft Sound Ratios” of male vs. female names develop roughly in parallel.
“Soft Sound Ratio” of male vs. female names .
Given the complexity of cultural phenomena such as naming preferences, we would of course hardly expect one factor alone to determine people’s choices. The QWERTY Effect, like the “Soft Sound” Preference, might well be one factor governing parents’ naming decisions. However, the experimental setups used so far to investigate the QWERTY hypothesis are much too prone to spurious correlations to provide convincing evidence for the idea that words with a higher RSA assume more positive valences because of their number of right-side letters.
Granted, the amount of experimental evidence assembled by Casasanto et al. for the QWERTY effect is impressive. Nevertheless, the correlations they find may well be spurious ones. Don’t get me wrong – I’m absolutely in favor of bold hypotheses (e.g. about Neanderthal language). But as a corpus linguist, I doubt that such a subtle preference can be meaningfully investigated using corpus-linguistic methods. As a corpus linguist, you’re always dealing with a lot of variables you can’t control for. This is not too big a problem if your research question is framed appropriately and if potential confounding factors are explicitly taken into account. But when it comes to a possible connection between single letters and emotional valence, the number of potential confounding factors just seems to outweigh the significance of an effect as subtle as the correlation between time and average RSA of baby names. In addition, some of the presumptions of the QWERTY studies would have to be examined independently: Does the average QWERTY user really use their left hand for typing left-side characters and their right hand for typing right-side characters – or are there significant differences between individual typing styles? How fluent is the average QWERTY user in typing? (The question of typing fluency is discussed in passing in the 2012 paper.)
The study of naming preferences entails even more potentially confounding variables. For example, if we assume that people want their children’s names to be as beautiful as possible not only in phonological, but also in graphemic terms, we could speculate that the form of letters (round vs. edgy or pointed) and the position of letters within the graphemic representation of a name play a more or less important role. In addition, you can’t control for, say, all names of persons that were famous in a given year and thus might have influenced parents’ naming choices.
If corpus analyses are, in my view, an inappropriate method to investigate the QWERTY effect, then what about behavioral experiments? In their 2012 paper, Jasmin & Casasanto have reported an experiment in which they elicited valence judgments for pseudowords to rule out possible frequency effects:
“In principle, if words with higher RSAs also had higher frequencies, this could result in a spurious correlation between RSA and valence. Information about lexical frequency was not available for all of the words from Experiments 1 and 2, complicating an analysis to rule out possible frequency effects. In the present experiment, however, all items were novel and, therefore, had frequencies of zero.”
Note, however, that they used phonologically well-formed stimuli such as pleek or ploke. These can be expected to yield associations to existing words such as, say, peak connotated) and poke, or speak and spoke, etc. It would be interesting to repeat this experiment with phonologically ill-formed pseudowords. (After all, participants were told they were reading words in an alien language – why shouldn’t this language only consist of consonants?) Furthermore, Casasanto & Chrysikou (2011) have shown that space-valence mappings can change fairly quickly following a short-term handicap (e.g. being unable to use your right hand as a right-hander). Considering this, it would be interesting to perform experiments using a different kind of keyboard, e.g. an ABCDE keyboard, a KALQ keyboard, or – perhaps the best solution – a keyboard in which the right and the left side of the QWERTY keyboard are simply inverted. In a training phase, participants would have to become acquainted with the unfamiliar keyboard design. In the test phase, then, pseudowords that don’t resemble words in the participants’ native language should be used to figure out whether an ABCDE-, KALQ-, or reverse QWERTY effect can be detected.
References
Casasanto, D. (2009). Embodiment of Abstract Concepts: Good and Bad in Right- and Left-Handers. Journal of Experimental Psychology: General 138, 351–367.
Casasanto, D., & Chrysikou, E. G. (2011). When Left Is “Right”. Motor Fluency Shapes Abstract Concepts. Psychological Science 22, 419–422.
Casasanto, D., Jasmin, K., Brookshire, G., & Gijssels, T. (2014). The QWERTY Effect: How typing shapes word meanings and baby names. In P. Bello, M. Guarini, M. McShane, & B. Scassellati (Eds.), Proceedings of the 36th Annual Conference of the Cognitive Science Society. Austin, TX: Cognitive Science Society.
Jasmin, K., & Casasanto, D. (2012). The QWERTY Effect: How Typing Shapes the Meanings of Words. Psychonomic Bulletin & Review 19, 499–504.
Littauer, R., Roberts, S., Winters, J., Bailes, R., Pleyer, M., & Little, H. (2014). From the Savannah to the Cloud. Blogging Evolutionary Linguistics Research. In L. McCrohon, B. Thompson, T. Verhoef, & H. Yamauchi, The Past, Present, and Future of Language Evolution Research. Student Volume following the 9th International Conference on the Evolution of Language (pp. 121–131).
Nübling, D. (2009). Von Monika zu Mia, von Norbert zu Noah. Zur Androgynisierung der Rufnamen seit 1945 auf prosodisch-phonologischer Ebene. Beiträge zur Namenforschung 44.
Language Evolution geeks may enjoy this Tragi-comic Opera in 3 acts with music by none other than Luc Steels! It tells the story of a humanoid robot called Casparo and explores themes of music, language, autonomy, love and the SINGULARITY. Also, if you care, if look very closely after 43 minutes you can see me in the choir at the right hand side.
There was an awful lot of talk about iconicity at this year’s EvoLang conference (as well as in previous years), and its ability to bootstrap communication systems and solve symbol grounding problems, and this has lead to talk on its possible role in the emergence of human language. Some work has been more sceptical than other’s about the role of iconicity, and so I thought it would be useful to do a wee overview of some of the talks I saw in relation to how different presenters define iconicity (though this is by no stretch a comprehensive overview).
As with almost everything, how people define iconicity differs across studies. In a recent paper, Monaghan, Shillcock, Christiansen & Kirby (2014) identify two forms of iconicity in language; absolute iconicity and relative iconicity. Absolute iconicity is where some linguistic feature imitates a referent, e.g. onomatopoeia or gestural pantomime. Relative iconicity is where there is a signal-meaning mapping or there is a correlation between similar signals and similar meanings. Relative iconicity is usually only clear when the whole meaning and signal spaces can be observed together and systematic relations can be observed between them.
Liz Irvine gave a talk on the core assumption that iconicity played a big role in in bootstrapping language. She teases apart the distinction above by calling absolute iconicity, “diagrammatic iconicity” and relative iconicity, “imagic iconicity”. “Imagic iconicity” can be broken down even further and can be measured on a continuum either in terms of how signals are used and interpreted by language users, or simply by objectively looking at meaning-signal mappings where signs can be non-arbitrary, but not necessarily treated as iconic by language users. Irvine claims that this distinction is important in accessing the role of iconicity in the emergence of language. She argues that diagrammatic or absolute iconicity may aid adults in understanding new signs, but it doesn’t necessarily aid early language learning in infants. Whereas imagic, or relative iconicity, is a better candidate to aid language acquisition and language emergence, where language users do not interpret the signal-meaning mappings explicitly as being iconic, even though they are non-arbitrary.
Irvine briefly discusses that ape gestures are not iconic from the perspective of their users. Marcus Perlman, Nathaniel Clark and Joanne A. Tanner presented work on whether iconicity exists in ape gesture. They define iconicity as being gestures which in any way resemble or depict their meanings but break down these gestures into pantomimed actions, directive touches and visible directives, which are all arguably examples of absolute iconicity. Following from Irvine’s arguments, this broad definition of iconicity may not be so useful when drawing up scenarios for language evolution, and the authors try to provide more detailed and nuanced analysis drawing from the interpretation of signs from the ape’s perspective. Theories which currently exist on iconicity in ape gesture maintain that any iconicity is an artefact of the gesture’s development through inheritance and ritualisation. However, the authors argue that these theories do not currently account for the variability and creativity seen in iconic ape gestures which may help frame iconicity from the perspective of its user.
It’s difficult to analyse iconicity from an ape’s perspective, however, it should be much easier to get at how human’s perceive and interpret different types of iconicity via experiments. I think that experimental design can help get at this, but also analysis from a user perspective from post-experimental questionnaires or even post-experimental experiments (where naive participants are asked to rate to what degree a sign represents a meaning).
Gareth Roberts and Bruno Galantucci presented a study where their hypothesis was that a modality’s capacity for iconicity may inhibit the emergence of combinatorial structure (phonological patterning) in a system. This hypothesis may explain why emerging sign languages, which have more capacity for iconicity than spoken languages, can have fully expressive systems without a level of combinatorial structure (see here). They used the now famous paradigm from Galantucci’s 2005 experiment here. They asked participants to communicate a variety of meanings which were either lines, which could be represented through absolute iconicity with the modality provided, or circles which were various shades of green, which could not be iconically represented. The experiment showed that indeed, the signals used for circles were made up from combinatorial elements where the lines retained iconicity throughout the experiment. This is a great experiment and I really like it, however, I worry that it is only looking at two extreme ends of the iconicity continuum, and has not considered the effects of relative iconicity, or nuances of signal-meaning relations. In de Boer and Verhoef (2012), a mathematical model shows that shared topology between signal and meaning spaces will generate an iconic system with signal-meaning mapping, but mismatched topologies will generate systems with conventionalised structure. I think it is important that experimental work now looks into more slight differences between signal and meaning spaces and the effects these differences will have on structure in emerging linguistic systems in the lab, and also how participant’s interpretation of any iconicity or structure in a system effects the nature of that iconicity or structure. I’m currently running some experiments exploring this myself, so watch this space!
References
Where possible, I’ve linked to studies as I’ve cited them.
All other studies cited are included in Erica A. Cartmill, Seán Roberts, Heidi Lyn & Hannah Cornish, ed., The Evolution of Language: Proceedings of the 10th international conference (EvoLang 10). It’s only £87.67 on Amazon, (but it may be wiser to email the authors if you don’t have a friend with a copy).
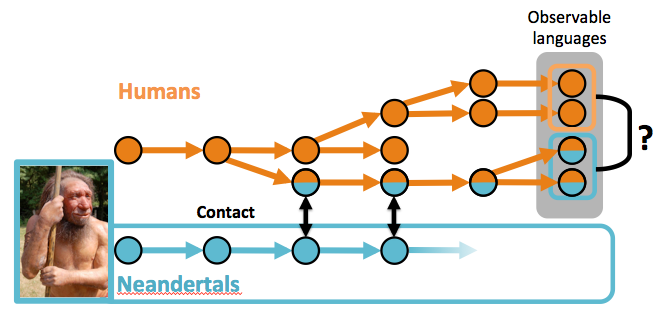
This week there’s an article about exploring Neandertal langauge in the New Scientist by Dan Dediu, Scott Moisik and I. It discusses the idea that if Neandertals spoke modern languages, and if there was cultural contact between us and them, then ancient human languages may have been affected by Neandertal language (borrowing, contact effects etc.). If this happened, then we may be able to detect these effects in today’s languages. The article and a recent blog post explains the idea, but I’ll cover some of the more technical stuff here.
Obviously, this is a very controversial idea: the time scale is much longer than the usual linguistic reconstruction and we have no direct evidence for Neandertals speaking complex languages. We’re definitely in for some flack. So, this post briefly covers what we actually did.
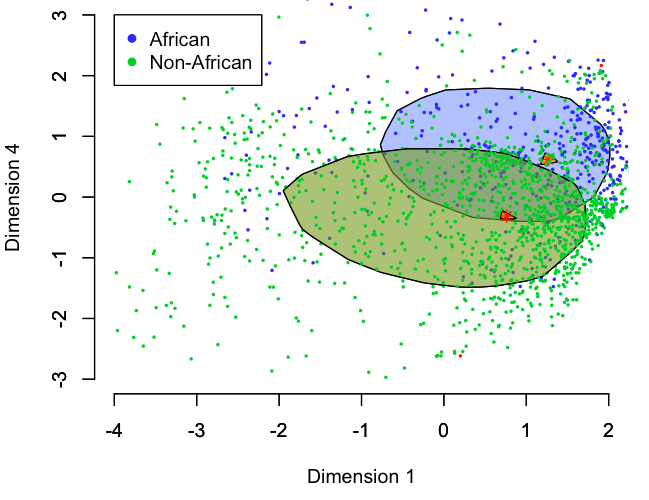
Our EvoLang paper (and a full paper in prep) asks whether one necessary condition for coming anywhere near providing evidence for this idea is true: Are there difference between current languages that were in contact (outside of Africa) and languages that were not in contact (inside Africa)? This has been addressed before, for different reasons (Cysouw & Comrie, 2009: pdf), but with a smaller sample of data.
Can we detect traces of contact with Neandertals in present day languages? One condition for this is there being statistical differences between contact and non-contact languages.
Using data from WALS, we ran a few tests:
STRUCTURE analysis: what is the most likely number of ‘founder’ populations that gives rise to the current diversity we see in African and Eurasian languages? Do the estimated founder populations align with African and non-African languages?
K-means clustering: does a ‘natural’ statistical division between the world’s languages reflect a division between African and non-African languages? (is it better than chance and better than other continents? Also run on phonetic data from PHOIBLE and lexical data from the ASJP)
Weighted multidimensional scaling: If we compress WALS to a few dimensions, does the first dimension reflect a distinction between African and non-African languages?
Phylogenetic reconstruction: We reconstruct the cultural evolution of present-day language families to see if African and non-African languages have different cultural evolutionary biases (e.g. more likely to move towards or away from particular traits). We used 3 phylogenies (WALS, Ethnologue, Glottolog), 3 branch length scaling assumptions (Grafen’s method, NNLS and UPGMA) and 3 methods of ancestral state reconstruction (Maximum parsimony, Maximum likelihood (BayesTraits) and Maximum likelihood (APE)). We searched for features that have opposing biases in African and non-African languages that are bigger than 95% of all comparisons and are robust across all assumptions.
Support Vector Machine learning: We trained a Support Vector Machine (a supervised machine learning algorithm) to tell the difference between African and non-African languages. We assessed the performance on unseen data, and also extract the most decisive linguistic features for making the distinction. We estimate the number of features needed to get good results.
Binary classification trees: This algorithm finds linguistic features to divide the data into sub-sets in a way that maximises the ease of differentiating African and non-African languages.
Results of a multidimensional scaling analysis of WALS, with African and non-African languages grouped by bag plots. The results differentiate African and non-African languages better than chance (p < 0.001) and better than other continent pairs (p = 0.004), but NOT better than 95% of linguistic variables (p = 0.06).
The detailed results will appear in our paper, but here’s what we conclude:
Some of the tests result in positive answers. For example, the support vector machine analysis could differentiate between African and non-African typologies with 93% accuracy. However, the algorithm needs at least linguistic 50 variables to make this distinction, so it’s unclear whether it’s picking up on actual differences, or just gaps in the data.
While some tests passed, our criterion was that ALL of the tests should pass for us to be at all confident of a statistical difference between African and non-African languages. Some tests fail, so we can’t support this.
However, most of the problems we ran into were due to a lack of data. We could get better estimates if we had more typological data of better quality from existing languages. Another problem was implicational universals – particular typological variables are correlated because they affect each other (e.g. verb-object order and prepositions/postpositions), causing patterns in the world’s languages that are confounded with geographic areas.
There’s a bigger question of whether, in theory, we can tell the difference between drift, contact effects, areal effects and language death. Contact with Neandertals may just be too far into the past, with too many human languages dying in the meantime, to make this distinction possible.
So, our conclusion is that any attempt to reconstruct Neandertal languages will fail with the current data and theory we have. Not surprising, really. The interesting thing, for me, is that we actually have methods that can give us quantitative answers about this idea, and the answer might change as we document more languages and develop theories about historical change and contact. As Chris Knight described our EvoLang presentation, this is one of my “most exciting and least conclusive” studies.
Remi van Trijp, a researcher at the Sony Computer Science Laboratory in Paris has started a weekly webcomic on the Evolution of Language here. There are seven entries so far, Remi adds some explanatory commentary to each one. Whilst somewhat crudely draw, they’re definitely worth a look. Here’s my favourite so far:
“Chomsky still rocks!” This comment on Twitter refers to a recent paper in PNAS by David M. Gómez et al. entitled “Language Universals at Birth”. Indeed, the question Gómez et al. address is one of the most hotly debated questions in linguistics: Does children’s language learning draw on innate capacities that evolved specifically for linguistic purposes – or rather on domain-general skills and capabilities?
Lbifs, Blifs, and Brains
Gómez and his colleagues investigate these questions by studying how children respond to different syllable structures:
It is well known that across languages, certain structures are preferred to others. For example, syllables like blif are preferred to syllables like bdif and lbif. But whether such regularities reflect strictly historical processes, production pressures, or universal linguistic principles is a matter of much debate. To address this question, we examined whether some precursors of these preferences are already present early in life. The brain responses of newborns show that, despite having little to no linguistic experience, they reacted to syllables like blif, bdif, and lbif in a manner consistent with adults’ patterns of preferences. We conjecture that this early, possibly universal, bias helps shaping language acquisition.
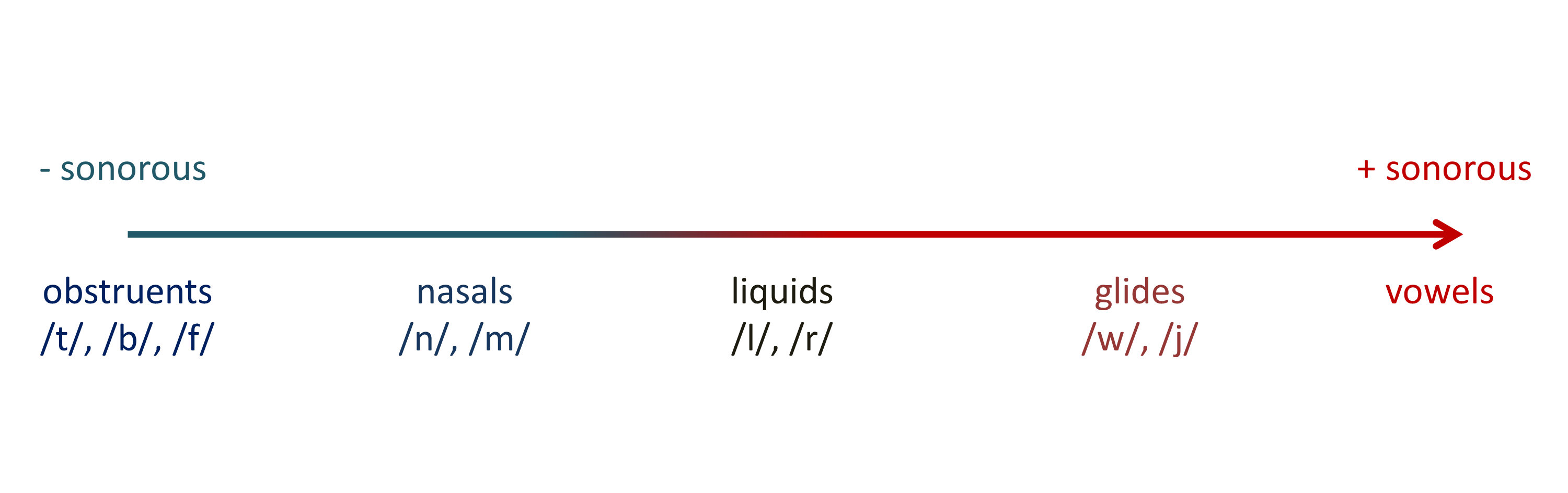
More specifically, they assume a restriction on syllable structure known as the Sonority Sequencing Principle (SSP), which has been proposed as “a putatively universal constraint” (p. 5837). According to this principle, “syllables maximize the sonority distance from their margins to their nucleus”. For example, in /blif/, /b/ is less sonorous than /l/, which is in turn less sonorous than the vowel /i/, which constitues the syllable’s nucleus. In /lbif/, by contrast, there is a sonority fall, which is why this syllable is extremely ill-formed according to the SSP.
A simplified version of the sonority scale
In a first experiment, Gómez et al. investigated “whether the brains of newborns react differentially to syllables that are well- or extremely ill-formed, as defined by the SSP” (p. 5838). They had 24 newborns listen to /blif/- and /lbif/-type syllables while measuring the infant’s brain activities. In the left temporal and right frontoparietal brain areas, “well-formed syllables elicited lower oxyhemoglobin concentrations than ill-formed syllables.” In a second experiment, they presented another group of 24 newborns with syllables either exhibiting a sonority rise (/blif/) or two consonants of the same sonority (e.g. /bdif/) in their onset. The latter option is dispreferred across languages, and previous behavioral experiments with adult speakers have also shown a strong preference for the former pattern. “Results revealed that oxyhemoglobin concentrations elicited by well-formed syllables are significantly lower than concentrations elicited by plateaus in the left temporal cortex” (p. 5839). However, in contrast to the first experiment, there is no significant effect in the right frontoparietal region, “which has been linked to the processing of suprasegmental properties of speech” (p. 5838).
In a follow-up experiment, Gómez et al. investigated the role of the position of the CC-patterns within the word: Do infants react differently to /lbif/ than to, say, /olbif/? Indeed, they do: “Because the sonority fall now spans across two syllables (ol.bif), rather than a syllable onset (e.g., lbif), such words should be perfectly well-formed. In line with this prediction, our results show that newborns’ brain responses to disyllables like oblif and olbif do not differ.”
How much linguistic experience do newborns have?
Taken together, these results indicate that newborn infants are already sensitive for syllabification (as the follow-up experiment suggests) as well as for certain preferences in syllable structure. This leads Gómez et al. to the conclusion “that humans possess early, experience-independent linguistic biases concerning syllable structure that shape language perception and acquisition” (p. 5840). This conjecture, however, is a very bold one. First of all, seeing these preferences as experience-independent presupposes the assumption that newborn infants do not have linguistic experience at all. However, there is evidence that “babies’ language learning starts from the womb”. In their classic 1986 paper, Anthony DeCasper and Melanie Spence showed that “third-trimester fetuses experience their mothers’ speech sounds and that prenatal auditory experience can influence postnatal auditory preferences.” Pregnant women were instructed to read aloud a story to their unborn children when they felt that the fetus was awake. In the postnatal phase, the infants’ reactions to the same or a different story read by their mother’s or another woman’s voice were studied by monitoring the newborns’ sucking behavior. Apart from the “experienced” infants who had been read the story, a group of “untrained” newborns were used as control subjects. They found that for experienced subjects, the target story was more reinforcing than a novel story, no matter if it was recited by their mother’s or a different voice. For the control subjects, by contrast, no difference between the stories could be found. “The only experimental variable that can systematically account for these findings is whether the infants’ mothers had recited the target story while pregnant” (DeCasper & Spence 1986: 143).
The problem of human origins, of which language origins is one aspect, is deep and important. It is also somewhat mysterious. If we could travel back in time at least some of those mysteries could be cleared up. One that interests me, for example, is whether or not the emergence of language was preceded by the emergence of music, or more likely, proto-music. Others are interested in the involvement of gesture in language origins.
Some of the attendant questions could be resolved by traveling back in time and making direct observations. Still, once we’d observed what happened and when it happened, questions would remain. We still wouldn’t know the neural and cognitive mechanisms, for they are not apparent from behavior alone. But our observations of just what happened would certainly constrain the space of models we’d have to investigate.
Unfortunately, we can’t travel back in time to make those observations. That difficulty has the peculiar effect of reversing the inferential logic of the previous paragraph. We find ourselves in the situation of using our knowledge of neural and cognitive mechanisms to constrain the space of possible historical sequences.
Except, of course, that our knowledge of neural and cognitive mechanisms is not very secure. And large swaths of linguistics are mechanism free. To be sure, there may be an elaborate apparatus of abstract formal mechanism, but just how that mechanism is realized in step-by-step cognitive and neural processes, that remains uninvestigated, except among computational linguists.
The upshot of all this is that we must approach these questions indirectly. We have to gather evidence from a wide variety of disciplines – archeology, physical and cultural anthropology, cognitive psychology, developmental psychology, and the neurosciences – and piece it together. Such work entails a level of speculation that makes well-trained academicians queasy.
❖❖❖
What follows is an out-take from Beethoven’s Anvil, my book on music. It’s about a thought experiment that first occurred to me while in graduate school in the mid-1970s. Consider the often astounding and sometimes absurd things that trainers can get animals to do, things the don’t do naturally. Those acts are, in some sense, inherent in their neuro-muscular endowment, but not evoked by their natural habitat. But place them in an environment ruled by humans who take pleasure in watching dancing horses, and . . . Except that I’m not talking about horses.
It seems to me that what is so very remarkable about the evolution of our own species is that the behavioral differences between us and our nearest biological relatives are disproportionate to the physical and physiological differences. The physical and physiological differences are relatively small, but the behavioral differences are large.
In thinking about this problem I have found it useful to think about how at least some chimpanzees came to acquire a modicum of language. All of them ended in failure. In the most intense of these efforts, Keith and Cathy Hayes raised a baby chimp in their household from 1947 to 1954. But that close and sustained interaction with Vicki, the young chimp in question, was not sufficient. Then in the late 1960s Allen and Beatrice Gardner began training a chimp, Washoe, in Ameslan, a sign language used among the deaf. This effort was far more successful. Within three years Washoe had a vocabulary of Ameslan 85 signs and she sometimes created signs of her own. Continue reading “UFO Events, a Thought Experiment about the Evolution of Language”
Recursion is one of the most important mechanisms that has been introduced into linguistics in the past six decades or so. It is also one of the most problematic and controversial. These days significant controversy centers on question of the emergence of recursion in the evolution of language. These informal remarks bear on that issue.
Recursion is generally regarded as an aspect of language syntax. My teacher, the late David Hays, had a somewhat different view. He regarded recursion as mechanism of the mind as a whole and so did not specifically focus on recursion in syntax. By the time I began studying with him his interest had shifted to semantics.
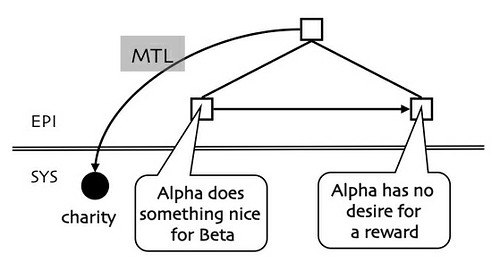
He had the idea that abstract concepts could be defined over stories. Thus: charity is when someone does something nice for someone without thought of a reward. We can represent that with the following diagram:
The charity node to the left is being defined by the structure of episodes at the right (the speech balloons are just dummies for a network structure). The head of the episodic structure is linked to the charity node with a metalingual arc (MTL), named after Jakobson’s metalingual function, which is language about language. So, one bit of language is defined by s complex pattern of language. Charity, of course, can appear in episodes defining other abstract stories, and so on, thus making the semantic system recursive.