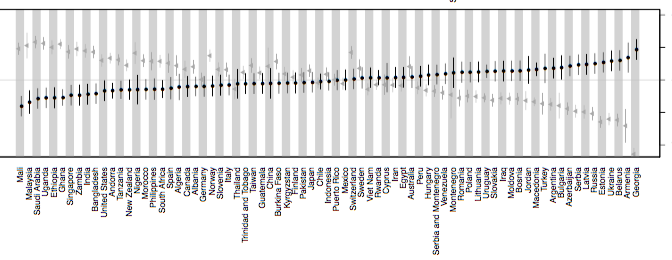
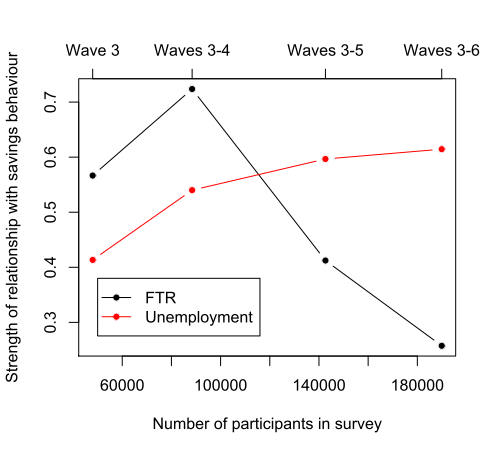
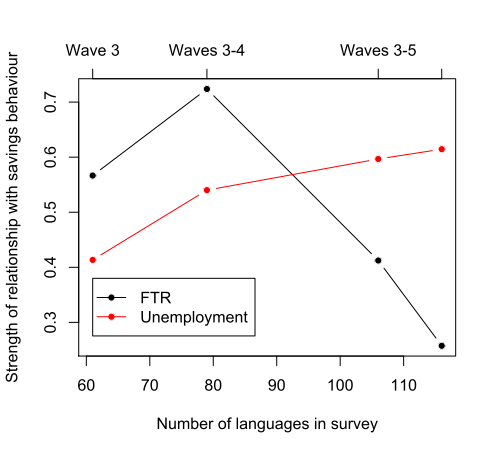
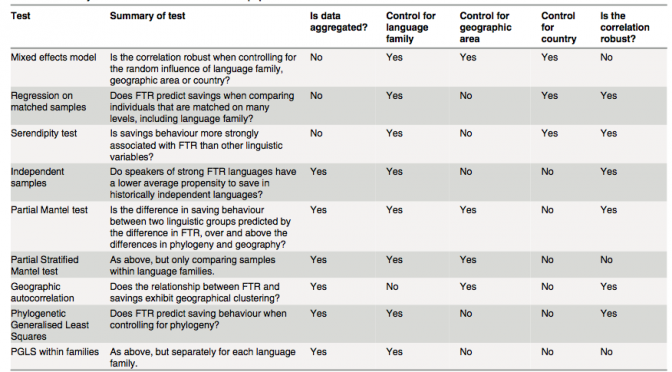
On Tuesday, July 21st, this year’s International Cognitive Linguistics Conference will host a theme session on “Cognitive Linguistics and the Evolution of Language” co-organized by three Replicated Typo authors: Michael Pleyer, James Winters, and myself. In addition, two Replicated Typo bloggers are co-authors on papers presented in the theme session.
The general idea of this session goes back to previous work by James and Michael, who promoted the idea of integrating Cognitive Linguistics and language evolution research in several conference talks as well as in a 2014 paper – published, quite fittingly, in a journal called “Theoria et Historia Scientiarum”, as the very idea of combining these frameworks requires some meta-theoretical reflection. As both cognitive and evolutionary linguistics are in themselves quite heterogeneous frameworks, the question emerges what we actually mean when we speak of “cognitive” or “evolutionary” linguistics, respectively.
I might come back to this meta-scientific discussion in a later post. For now, I will confine myself to giving a brief overview of the eight talks in our session. The full abstracts can be found here.
In the first talk, Vyv Evans (Bangor) proposes a two-step scenario of the evolution of language, informed by concepts from Cognitive Linguistics in general and Langacker’s Cognitive Grammar in particular:
The first stage, logically, had to be a symbolic reference in what I term a words-to-world direction, bootstrapping extant capacities that Autralopithecines, and later ancestral Homo shared with the great apes. But the emergence of a grammatical capacity is also associated with a shift towards a words-to-words direction symbolic reference: words and other grammatical constructions can symbolically refer to other symbolic units.
Roz Frank (Iowa) then outlines “The relevance of a ‘Complex Adaptive Systems’ approach to ‘language’” – note the scarequotes. She argues that “the CAS approach serves to replace older historical linguistic notions of languages as ‘organisms’ and as ‘species’”.
Sabine van der Ham, Hannah Little, Kerem Eryılmaz, and Bart de Boer (Brussels) then talk about two sets of experiments investigating the role of individual learning biases and cultural transmission in shaping language, in a talk entitled “Experimental Evidence on the Emergence of Phonological Structure”.
In the next talk, Seán Roberts and Stephen Levinson (Nijmegen) provide experimental evidence for the hypothesis that “On-line pressures from turn taking constrain the cultural evolution of word order”. Chris Sinha’s talk, entitled “Eco-Evo-Devo: Biocultural synergies in language evolution”, is more theoretical in nature, but no less interesting. Starting from the hypothesis that “many species construct “artefactual” niches, and language itself may be considered as a transcultural component of the species-specific human biocultural niche”, he argues that
Treating language as a biocultural niche yields a new perspective on both the human language capacity and on the evolution of this capacity. It also enables us to understand the significance of language as the symbolic ground of the special subclass of symbolic cognitive artefacts.
Arie Verhagen (Leiden) then discusses the question if public and private communication are “Stages in the Evolution of Language”. He argues against Tomasello’s idea that ““joint” intentionality emerged first and evolved into what is essentially still its present state, which set the stage for the subsequent evolution of “collective” intentionality” and instead defends the view that
these two kinds of processes and capacities evolved ‘in tandem’: A gradual increase in the role of culture (learned patterns of behaviour) produced differences and thus competition between groups of (proto-)humans, which in turn provided selection pressures for an increased capability and motivation of individuals to engage in collaborative activities with others.
James Winters (Edinburgh) then provides experimental evidence that “Linguistic systems adapt to their contextual niche”, addressing two major questions with the help of an artificial-language communication game:
(i) To what extent does the situational context influence the encoding of features in the linguistic system? (ii) How does the effect of the situational context work its way into the structure of language?
His results “support the general hypothesis that language structure adapts to the situational contexts in which it is learned and used, with short-term strategies for conveying the intended meaning feeding back into long-term, system-wider changes.”
The final talk, entitled “Communicating events using bodily mimesis with and without vocalization” is co-authored by Jordan Zlatev, Sławomir Wacewicz, Przemysław Żywiczyński, andJoost van de Weijer (Lund/Torun). They introduce an experiment on event communication and discuss to what extent the greater potential for iconic representation in bodily reenactment compared to in vocalization might lend support for a “bodily mimesis hypothesis of language origins”.
In the closing session of the workshop, this highly promising array of papers is discussed with one of the “founding fathers” of modern language evolution research, Jim Hurford (Edinburgh).
But that’s not all: Just one coffee break after the theme session, there will be a panel on “Language and Evolution” in the general session of the conference, featuring papers by Gareth Roberts & Maryia Fedzechkina; Jonas Nölle; Carmen Saldana, Simon Kirby & Kenny Smith; Yasamin Motamedi, Kenny Smith, Marieke Schouwstra & Simon Kirby; and Andrew Feeney.