The MPI for Mathematics in the Sciences in Leipzig is hosting a workshop on Causality in the Language Sciences on April 13 – 15, 2015.
There is a call for talks and posters here (deadline January 10th, 2015).
Invited speakers include Balthasar Bickel, Claire Bowern, Morten Christiansen, Dan Dediu, Michael Dunn, T. Florian Jaeger, Gerhard Jaeger, Anne Kandler and Richard Sproat.
From the conference website:
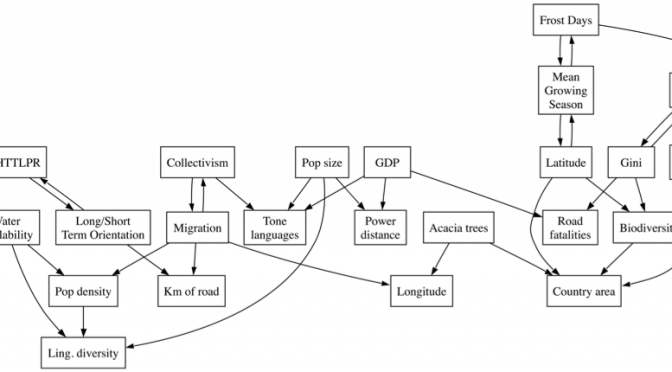
Although the tenet of “correlation does not imply causation” is still an important guiding principle in language research, a number of techniques developed in the last few decades opened new scenarios where testing causal relations becomes possible. Recent advances in information theory, time series analysis, phylogenetics, stochastic processes, dynamical systems, graphical models and Bayesian inference (among many others) set the stage for a new and exciting chapter in the field.
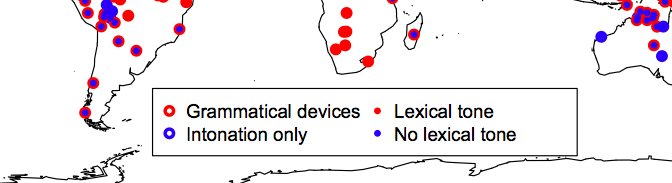
In parallel, in the last few decades an unprecedented amount of data became available on a large number of language-related phenomena. We have massive matrices of voxel activation in the neural circuits involved in speech production and comprehension, several years of annotated conversations between young children and their caregivers, hundreds of hours of phonetic and anatomical measurements and multiple environmental, genetic, and demographic variables related to populations of speakers for a large number of the world’s languages.
The aim of this workshop is to address these two issues: how do we properly test causal relations in (eventually noisy, sparse or incomplete) data, and how can we infer or test the mechanisms underlying them?
Following a half a day school on cutting-edge methods for causal analysis, world class scientists will present their research on topics ranging from language history, writing systems, speech processing, typology, lexical semantics, and others.
We invite contributions from researchers facing specific problems in determining causality in language systems and also from researchers offering perspectives from the methodological and theoretical point of view of causal inference.