If you read my last post here at Replicated Typo to the very end, you may remember that I promised to recommend a book and to return to one of the topics of this previous post. I won’t do this today, but I promise I will catch up on it in due time.
What I just did – promising something – is a nice example for one of the two functions of language which Vyvyan Evans from Bangor University distinguished in his talk on “The Human Meaning-Making Engine” yesterday at the UK Cognitive Linguistics Conference. More specifically, the act of promising is an example for the interactive function of language, which is of course closely intertwined with its symbolic function. Evans proposed two different sources for this two functions. The interactive function, he argued, arises from the human instinct for cooperation, whereas meaning arises from the interaction between the linguistic and the conceptual system. While language provides the “How” of meaning-making, the conceptual system provides the “What”. Evans used some vivid examples (e.g. this cartoon exemplifying nonverbal communication) to make clear that communication is not contingent on language. However, “language massively amplifies our communicative potential.” The linguistic system, he argued, has evolved as an executive control system for the conceptual system. While the latter is broadly comparable with that of other animals, especially great apes, the linguistic system is uniquely human. What makes it unique, however, is not the ability to refer to things in the world, which can arguably be found in other animals, as well. What is uniquely human, he argued, is the ability to symbolically refer in a sign-to-sign (word-to-word) direction rather than “just” in a sign-to-world (word-to-world) direction. Evans illustrated this “word-to-word” direction with Hans-Jörg Schmid’s (e.g. 2000; see also here) work on “shell nouns”, i.e. nouns “used in texts to refer to other passages of the text and to reify them and characterize them in certain ways.” For instance, the stuff I was talking about in the last paragraph would be an example of a shell noun.
According to Evans, the “word-to-word” direction is crucial for the emergence of e.g. lexical categories and syntax, i.e. the “closed-class” system of language. Grammaticalization studies indicate that the “open-class” system of human languages is evolutionarily older than the “closed-class” system, which is comprised of grammatical constructions (in the broadest sense). However, Evans also emphasized that there is a lot of meaning even in closed-class constructions, as e.g. Adele Goldberg’s work on argument structure constructions shows: We can make sense of a sentence like “Someone somethinged something to someone” although the open-class items are left unspecified.
Constructions, he argued, index or cue simulations, i.e. re-activations of body-based states stored in cortical and subcortical brain regions. He discussed this with the example of the cognitive model for Wales: We know that Wales is a geographical entity. Furthermore, we know that “there are lots of sheep, that the Welsh play Rugby, and that they dress in a funny way.” (Sorry, James. Sorry, Sean.) Oh, and “when you’re in Wales, you shouldn’t say, It’s really nice to be in England, because you will be lynched.”
On a more serious note, the cognitive models connected to closed-class constructions, e.g. simple past -ed or progressive -ing, are of course much more abstract but can also be assumed to arise from embodied simulations (cf. e.g. Bergen 2012). But in addition to the cognitive dimension, language of course also has a social and interactive dimension drawing on the apparently instinctive drive towards cooperative behaviour. Culture (or what Tomasello calls “collective intentionality”) is contigent on this deep instinct which Levinson (2006) calls the “human interaction engine”. Evans’ “meaning-making engine” is the logical continuation of this idea.
Just like Evans’ theory of meaning (LCCM theory), his idea of the “meaning-making engine” is basically an attempt at integrating a broad variety of approaches into a coherent model. This might seem a bit eclectic at first, but it’s definitely not the worst thing to do, given that there is significant conceptual overlap between different theories which, however, tends to be blurred by terminological incongruities. Apart from Deacon’s (1997) “Symbolic Species” and Tomasello’s work on shared and joint intentionality, which he explicitly discussed, he draws on various ideas that play a key role in Cognitive Linguistics. For example, the distinction between open- and closed-class systems features prominently in Talmy’s (2000) Cognitive Semantics, as does the notion of the human conceptual system. The idea of meaning as conceptualization and embodied simulation of course goes back to the groundbreaking work of, among others, Lakoff (1987) and Langacker (1987, 1991), although empirical support for this hypothesis has been gathered only recently in the framework of experimental semantics (cf. Matlock & Winter forthc. – if you have an account at academia.edu, you can read this paper here). All in all, then, Evans’ approach might prove an important further step towards integrating Cognitive Linguistics and language evolution research, as has been proposed by Michael and James in a variety of talks and papers (see e.g. here).
Needless to say, it’s impossible to judge from a necessarily fairly sketchy conference presentation if this model qualifies as an appropriate and comprehensive account of the emergence of meaning. But it definitely looks promising and I’m looking forward to Evans’ book-length treatment of the topics he touched upon in his talk. For now, we have to content ourselves with his abstract from the conference booklet:
In his landmark work, The Symbolic Species (1997), cognitive neurobiologist Terrence Deacon argues that human intelligence was achieved by our forebears crossing what he terms the “symbolic threshold”. Language, he argues, goes beyond the communicative systems of other species by moving from indexical reference – relations between vocalisations and objects/events in the world — to symbolic reference — the ability to develop relationships between words — paving the way for syntax. But something is still missing from this picture. In this talk, I argue that symbolic reference (in Deacon’s terms), was made possible by parametric knowledge: lexical units have a type of meaning, quite schematic in nature, that is independent of the objects/entities in the world that words refer to. I sketch this notion of parametric knowledge, with detailed examples. I also consider the interactional intelligence that must have arisen in ancestral humans, paving the way for parametric knowledge to arise. And, I also consider changes to the primate brain-plan that must have co-evolved with this new type of knowledge, enabling modern Homo sapiens to become so smart.
References
Bergen, Benjamin K. (2012): Louder than Words. The New Science of How the Mind Makes Meaning. New York: Basic Books.
Deacon, Terrence W. (1997): The Symbolic Species. The Co-Evolution of Language and the Brain. New York, London: Norton.
Lakoff, George (1987): Women, Fire, and Dangerous Things. What Categories Reveal about the Mind. Chicago: The University of Chicago Press.
Langacker, Ronald W. (1987): Foundations of Cognitive Grammar. Vol. 1. Theoretical Prerequisites. Stanford: Stanford University Press.
Langacker, Ronald W. (1991): Foundations of Cognitive Grammar. Vol. 2. Descriptive Application. Stanford: Stanford University Press.
Levinson, Stephen C. (2006): On the Human “Interaction Engine”. In: Enfield, Nick J.; Levinson, Stephen C. (eds.): Roots of Human Sociality. Culture, Cognition and Interaction. Oxford: Berg, 39–69.
Matlock, Teenie & Winter, Bodo (forthc): Experimental Semantics. In: Heine, Bernd; Narrog, Heiko (eds.): The Oxford Handbook of Linguistic Analysis. 2nd ed. Oxford: Oxford University Press.
Schmid, Hans-Jörg (2000): English Abstract Nouns as Conceptual Shells. From Corpus to Cognition. Berlin, New York: De Gruyter (Topics in English Linguistics, 34).
Talmy, Leonard (2000): Toward a Cognitive Semantics. 2 vol. Cambridge, Mass: MIT Press.
Shigeru Miyagawa, Shiro Ojima, Robert Berwick and Kazuo Okanoya have recently published a new paper in Frontiers in Psychology, which can be seen as a follow-up to the 2013 Frontiers paper by Miyagawa, Berwick and Okanoya (see Hannah’s post on this paper). While the earlier paper introduced what they call the “Integration Hypothesis of Human Language Evolution”, the follow-up paper seeks to provide empirical evidence for this theory and discusses potential challenges to the Integration Hypothesis.
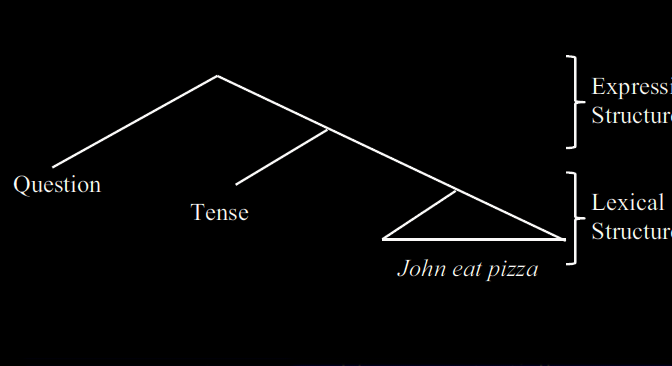
The basic idea of the Integration Hypothesis, in a nutshell, is this: “All human language sentences are composed of two meaning layers” (Miyagawa et al. 2013: 2), namely “E” (for “expressive”) and “L” (for “lexical”). For example, sentences like “John eats a pizza”, “John ate a pizza”, and “Did John eat a pizza?” are supposed to have the same lexical meaning, but they vary in their expressive meaning. Miyagawa et al. point to some parallels between expressive structure and birdsong on the one hand and lexical structure and the alarm calls of non-human primates on the other. More specifically, “birdsongs have syntax without meaning” (Miyagawa et al. 2014: 2), whereas alarm calls consist of “isolated uttered units that correlate with real-world references” (ibid.). Importantly, however, even in human language, the Expression Structure (ES) only admits one layer of hierarchical structure, while the Lexical Structure (LS) does not admit any hierarchical structure at all (Miyagawa et al. 2013: 4). The unbounded hierarchical structure of human language (“discrete infinity”) comes about through recursive combination of both types of structure.
This is an interesting hypothesis (“interesting” being a convenient euphemism for “well, perhaps not that interesting after all”). Let’s have a closer look at the evidence brought forward for this theory.
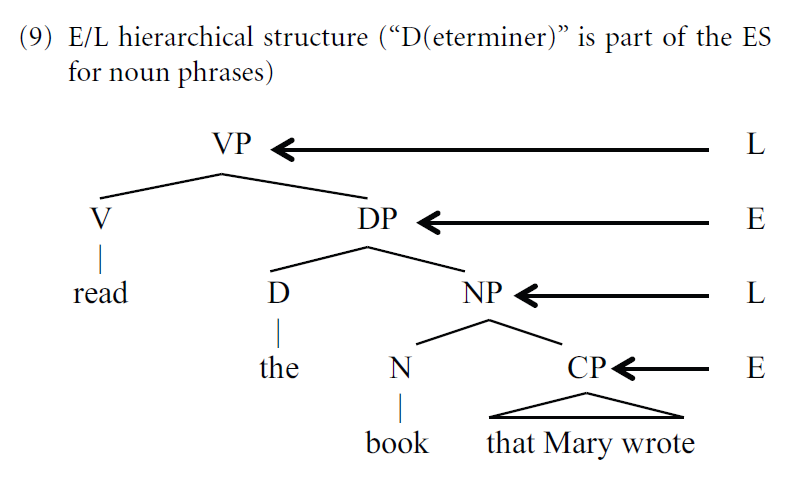
Miyagawa et al. “focus on the structures found in human language” (Miyagawa et al. 2014: 1), particularly emphasizing the syntactic structure of sentences and the internal structure of words. In a sentence like “Did John eat pasta?”, the lexical items John, eat, and pasta constitute the LS, while the auxiliary do, being a functional element, is seen as belonging to the expressive layer. In a more complex sentence like “John read the book that Mary wrote”, the VP and NP notes are allocated to the lexical layer, while the DP and CP nodes are allocated to the expressive layer.
Fig. 9 from Miyagawa et al. (2014), illustrating how unbounded hierarchical structure emerges from recursive combination of E- and L-level structures
As pointed out above, LS elements cannot directly combine with each other according to Miyagawa et al. (the ungrammaticality of e.g. John book and want eat pizza is taken as evidence for this), while ES is restricted to one layer of hierarchical structure. Discrete infinity then arises through recursive application of two rules:
(i) EP → E LP
(ii) LP → L EP
Rule (i) states that the E category can combine with LP to form an E-level structure. Rule (ii) states that the L category can combine with an E-level structure to form an L-level structure. Together, these two rules suffice to yield arbitrarily deep hierarchical structures.
The alternation between lexical and expressive elements, as exemplified in Figure (3) from the 2014 paper (= Figure 9 from the 2013 paper, reproduced above), is thus essential to their theory since they argue that “inside E and L we only find finite-state processes” (Miyagawa et al. 2014: 3). Several phenomena, most notably Agreement and Movement, are explained as “linking elements” between lexical and functional heads (cf. also Miyagawa 2010). A large proportion of the 2014 paper is therefore dedicated to phenomena that seem to argue against this hypothesis.
For example, word-formation patterns that can be applied recursively seem to provide a challenge for the theory, cf. example (4) in the 2014 paper:
(4) a. [anti-missile]
b. [anti-[anti-missile]missile] missile
The ostensible point is that this formation can involve center embedding, which would constitute a non-finite state construction.
However, they propose a different explanation:
When anti– combines with a noun such as missile, the sequence anti-missile is a modifier that would modify a noun with this property, thus, [anti-missile]-missile, [anti-missile]-defense. Each successive expansion forms via strict adjacency, (…) without the need to posit a center embedding, non-regular grammar.
Similarly, reduplication is re-interpreted as a finite state process. Furthermore, they discuss N+N compounds, which seems to violate “the assumption that L items cannot combine directly — any combination requires intervention from E.” However, they argue that the existence of linking elements in some languages provides evidence “that some E element does occur between the two L’s”. Their example is German Blume-n-wiese ‘flower meadow’, others include Freundeskreis ‘circle of friends’ or Schweinshaxe ‘pork knuckle’. It is commonly assumed that linking elements arose from grammatical markers such as genitive -s, e.g. Königswürde ‘royal dignity’ (from des Königs Würde ‘the king’s dignity’). In this example, the origin of the linking element is still transparent. The -es- in Freundeskreis, by contrast, is an example of a so-called unparadigmatic linking element since it literally translates to ‘circle of a friend’. In this case as well as in many others, the linking element cannot be traced back directly to a grammatical affix. Instead, it seems plausible to assume that the former inflectional suffix was reanalyzed as a linking element from the paradigmatic cases and subsequently used in other compounds as well.
To be sure, the historical genesis of German linking elements doesn’t shed much light on their function in present-day German, which is subject to considerable debate. Keeping in mind that these items evolved gradually however raises the question how the E and L layers of compounds were linked in earlier stages of German (or any other language that has linking elements). In addition, there are many German compounds without a linking element, and in other languages such as English, “linked” compounds like craft-s-man are the exception rather than the rule. Miyagawa et al.’s solution seems a bit too easy to me: “In the case of teacup, where there is no overt linker, we surmise that a phonologically null element occurs in that position.”
As an empiricist, I am of course very skeptical towards any kind of null element. One could possibly rescue their argument by adopting concepts from Construction Grammar and assigning E status to the morphological schema [N+N], regardless of the presence or absence of a linking element, but then again, from a Construction Grammar point of view, assuming a fundamental dichotomy between E and L structures doesn’t make much sense in the first place. That said, I must concede that the E vs. L distinction reflects basic properties of language that play a role in any linguistic theory, but especially in Construction Grammar and in Cognitive Linguistics. On the one hand, it reflects the rough distinction between “open-class” and “closed-class” items, which plays a key role in Talmy’s (2000) Cognitive Semantics and in the grammaticalization literature (cf. e.g. Hopper & Traugott 2003). As many grammaticalization studies have shown, most if not all closed-class items are “fossils” of open-class items. The abstract concepts they encode (e.g. tense or modality) are highly relevant to our everyday experience and, consequently, to our communication, which is why they got grammaticized in the first place. As Rose (1973: 516) put it, there is no need for a word-formation affix deriving denominal verbs meaning “grasp NOUN in the left hand and shake vigorously while standing on the right foot in a 2 ½ gallon galvanized pail of corn-meal-mush”. But again, being aware of the historical emergence of these elements begs the question if a principled distinction between the meanings of open-class vs. closed-class elements is warranted.
On the other hand, the E vs. L distinction captures the fundamental insight that languages pair form with meaning. Although they are explicitly talking about the “duality of semantics“, Miyagawa et al. frequently allude to formal properties of language, e.g. by linking up syntactic strutures with the E layer:
The expression layer is similar to birdsongs; birdsongs have specific patterns, but they do not contain words, so that birdsongs have syntax without meaning (Berwick et al., 2012), thus it is of the E type.
While the “expression” layer thus seems to account for syntactic and morphological structures, which are traditionally regarded as purely “formal” and meaningless, the “lexical” layer captures the referential function of linguistic units, i.e. their “meaning”. But what is meaning, actually? The LS as conceptualized by Miyagawa et al. only covers the truth-conditional meaning of sentences, or their “conceptual content”, as Langacker (2008) calls it. From a usage-based perspective, however, “an expression’s meaning consists of more than conceptual content – equally important to linguistic semantics is how that content is shaped and construed.” (Langacker 2002: xv) According to the Integration Hypothesis, this “construal” aspect is taken care of by closed-class items belonging to the E layer. However, the division of labor envisaged here seems highly idealized. For example, tense and modality can be expressed using open-class (lexical) items and/or relying on contextual inference, e.g. German Ich gehe morgen ins Kino ‘I go to the cinema tomorrow’.
It is a truism that languages are inherently dynamic, exhibiting a great deal of synchronic variation and diachronic change. Given this dynamicity, it seems hard to defend the hypothesis that a fundamental distinction between E and L structures which cannot combine directly can be found universally in the languages of the world (which is what Miyagawa et al. presuppose). We have already seen that in the case of compounds, Miyagawa et al. have to resort to null elements in order to uphold their hypothesis. Furthermore, it seems highly likely that some of the “impossible lexical structures” mentioned as evidence for the non-combinability hypothesis are grammatical at least in some creole languages (e.g. John book, want eat pizza).
In addition, it seems somewhat odd that E- and L-level structures as “relics” of evolutionarily earlier forms of communication are sought (and expected to be found) in present-day languages, which have been subject to millennia of development. This wouldn’t be a problem if the authors were not dealing with meaning, which is not only particularly prone to change and variation, but also highly flexible and context-dependent. But even if we assume that the existence of E-layer elements such as affixes and other closed-class items draws on innate dispositions, it seems highly speculative to link the E layer with birdsong and the L layer with primate calls on semantic grounds.
The idea that human language combines features of birdsong with features of primate alarm calls is certainly not too far-fetched, but the way this hypothesis is defended in the two papers discussed here seems strangely halfhearted and, all in all, quite unconvincing. What is announced as “providing empirical evidence” turns out to be a mostly introspective discussion of made-up English example sentences, and if the English examples aren’t convincing enough, the next best language (e.g. German) is consulted. (To be fair, in his monograph, Miyagawa (2010) takes a broader variety of languages into account.) In addition, much of the discussion is purely theory-internal and thus reminiscent of what James has so appropriately called “Procrustean Linguistics“.
To their credit, Miyagawa et al. do not rely exclusively on theory-driven analyses of made-up sentences but also take some comparative and neurological studies into account. Thus, the Integration Hypothesis – quite unlike the “Mystery” paper (Hauser et al. 2014) co-authored by Berwick and published in, you guessed it, Frontiers in Psychology (and insightfully discussed by Sean) – might be seen as a tentative step towards bridging the gap pointed out by Sverker Johansson in his contribution to the “Perspectives on Evolang” section in this year’s Evolang proceedings:
A deeper divide has been lurking for some years, and surfaced in earnest in Kyoto 2012: that between Chomskyan biolinguistics and everybody else. For many years, Chomsky totally dismissed evolutionary linguistics. But in the past decade, Chomsky and his friends have built a parallel effort at elucidating the origins of language under the label ‘biolinguistics’, without really connecting with mainstream Evolang, either intellectually or culturally. We have here a Kuhnian incommensurability problem, with contradictory views of the nature of language.
On the other hand, one could also see the Integration Hypothesis as deepening the gap since it entirely draws on generative (or “biolinguistic”) preassumptions about the nature of language which are not backed by independent empirical evidence. Therefore, to conclusively support the Integration Hypothesis, much more evidence from many different fields would be necessary, and the theoretical preassumptions it draws on would have to be scrutinized on empirical grounds, as well.
References
Hauser, Marc D.; Yang, Charles; Berwick, Robert C.; Tattersall, Ian; Ryan, Michael J.; Watumull, Jeffrey; Chomsky, Noam; Lewontin, Richard C. (2014): The Mystery of Language Evolution. In: Frontiers in Psychology 4. doi: 10.3389/fpsyg.2014.00401
Hopper, Paul J.; Traugott, Elizabeth Closs (2003): Grammaticalization. 2nd ed. Cambridge: Cambridge University Press.
Johansson, Sverker: Perspectives on Evolang. In: Cartmill, Erica A.; Roberts, Séan; Lyn, Heidi; Cornish, Hannah (eds.) (2014): The Evolution of Language. Proceedings of the 10th International Conference. Singapore: World Scientific, 14.
Langacker, Ronald W. (2002): Concept, Image, and Symbol. The Cognitive Basis of Grammar. 2nd ed. Berlin, New York: De Gruyter (Cognitive Linguistics Research, 1).
Langacker, Ronald W. (2008): Cognitive Grammar. A Basic Introduction. Oxford: Oxford University Press.
Miyagawa, Shigeru (2010): Why Agree? Why Move? Unifying Agreement-Based and Discourse-Configurational Languages. Cambridge: MIT Press (Linguistic Inquiry, Monographs, 54).
Miyagawa, Shigeru; Berwick, Robert C.; Okanoya, Kazuo (2013): The Emergence of Hierarchical Structure in Human Language. In: Frontiers in Psychology 4. doi 10.3389/fpsyg.2013.00071
Miyagawa, Shigeru; Ojima, Shiro; Berwick, Robert C.; Okanoya, Kazuo (2014): The Integration Hypothesis of Human Language Evolution and the Nature of Contemporary Languages. In: Frontiers in Psychology 5. doi 10.3389/fpsyg.2014.00564
Rose, James H. (1973): Principled Limitations on Productivity in Denominal Verbs. In: Foundations of Language 10, 509–526.
Talmy, Leonard (2000): Toward a Cognitive Semantics. 2 vol. Cambridge, Mass: MIT Press.
P.S.: After writing three posts in a row in which I critizised all kinds of studies and papers, I herby promise that in my next post, I will thoroughly recommend a book and return to a question raised only in passing in this post. [*suspenseful cliffhanger music*]
Oh wait, I’m not a guest anymore. Thanks to James for inviting me to become a regular contributor to Replicated Typo. I hope I will have to say some interesting things about the evoution of language, cognition, and culture, and I promise that I’ll try to keep my next posts a bit shorter than the guest post two weeks ago.
Today I’d like to pick up on an ongoing discussion over at Language Log. In a series of blog posts in early 2012, Mark Liberman has taken issue with the so-called “QWERTY effect”. The QWERTY effect seems like an ideal topic for my first regular post as it is tightly connected to some key topics of Replicated Typo: Cultural evolution, the cognitive basis of language, and, potentially, spurious correlations. In addition, Liberman’s coverage of the QWERTY effect has spawned an interesting discussion about research blogging (cf. Littauer et al. 2014).
But what is the QWERTY effect, actually? According to Kyle Jasmin and Daniel Casasanto (Jasmin & Casasanto 2012), the written form of words can influence their meaning, more particularly, their emotional valence. The idea, in a nutshell, is this: Words that contain more characters from the right-hand side of the QWERTY keyboard tend to “acquire more positive valences” (Jasmin & Casasanto 2012). Casasanto and his colleagues tested this hypothesis with a variety of corpus analyses and valence rating tasks.
Whenever I tell fellow linguists who haven’t heard of the QWERTY effect yet about these studies, their reactions are quite predictable, ranging from “WHAT?!?” to “asdf“. But unlike other commentors, I don’t want to reject the idea that a QWERTY effect exists out of hand. Indeed, there is abundant evidence that “right” is commonly associated with “good”. In his earlier papers, Casasanto provides quite convincing experimental evidence for the bodily basis of the cross-linguistically well-attested metaphors RIGHT IS GOOD and LEFT IS BAD (e.g. Casasanto 2009). In addition, it is fairly obvious that at the end of the 20th century, computer keyboards started to play an increasingly important role in our lives. More and more people have full size keyboards somewhere in their home. Also, it seems legitimate to assume that in a highly literate society, written representations of words form an important part of our linguistic knowledge. Given these factors, the QWERTY effect is not such an outrageous idea. However, measuring it by determining the “Right-Side Advantage” of words in corpora is highly problematic since a variety of potential confounding factors are not taken into account.
Finding the Right Name(s)
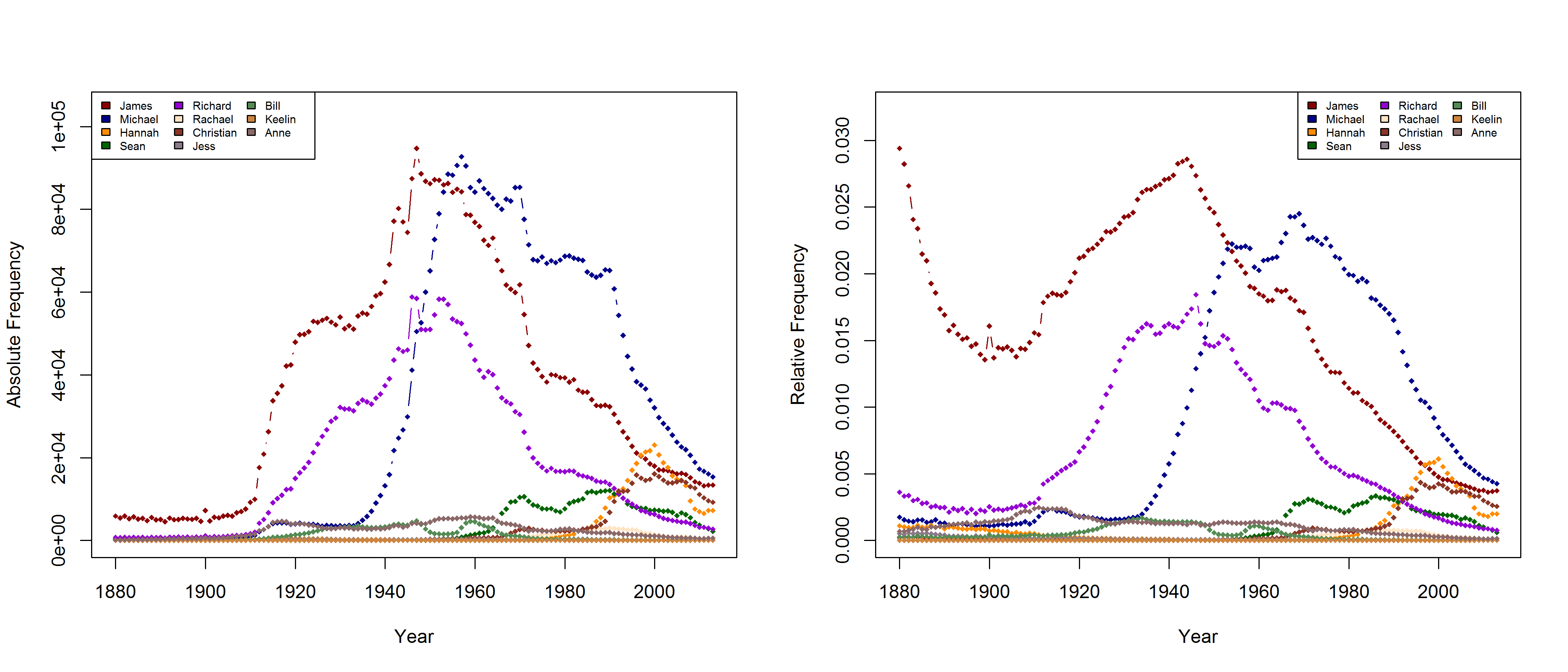
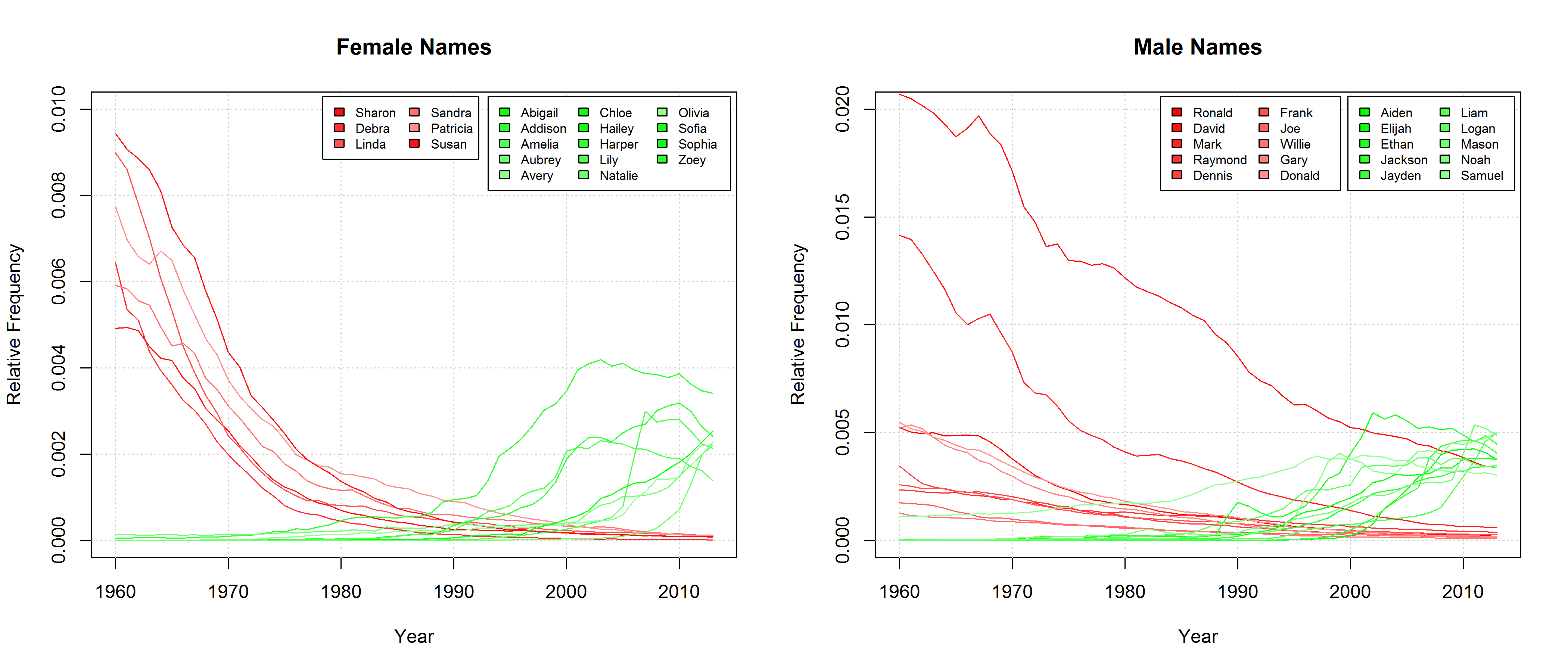
Frequencies of some (almost) randomly selected names in the USA.
In a new CogSci paper, Casasanto, Jasmin, Geoffrey Brookshire, and Tom Gijssels present five new experiments to support the QWERTY hypothesis. Since I am based at a department with a strong focus on onomastics, I found their investigation of baby names particularly interesting. Drawing on data from the US Social Security Administration website, they analyze all names that have been given to more than 100 babys in every year from 1960 to 2012. To determine the effect of keyboard position, they use a measure they call “Right Side Adventage” (RSA): [(#right-side letters)-(#left-side letters)]. They find that
“that the mean RSA has increased since the popularization of the QWERTY keyboard, as indicated by a correlation between the year and average RSA in that year (1960–2012, r = .78, df = 51, p =8.6 × 10-12“
In addition,
“Names invented after 1990 (n = 38,746) use more letters from the right side of the keyboard than names in use before 1990 (n = 43,429; 1960–1990 mean RSA = -0.79; 1991–2012 mean RSA = -0.27, t(81277.66) = 33.3, p < 2.2 × 10-16 […]). This difference remained significant when length was controlled by dividing each name’s RSA by the number of letters in the name (t(81648.1) = 32.0, p < 2.2 × 10-16)”
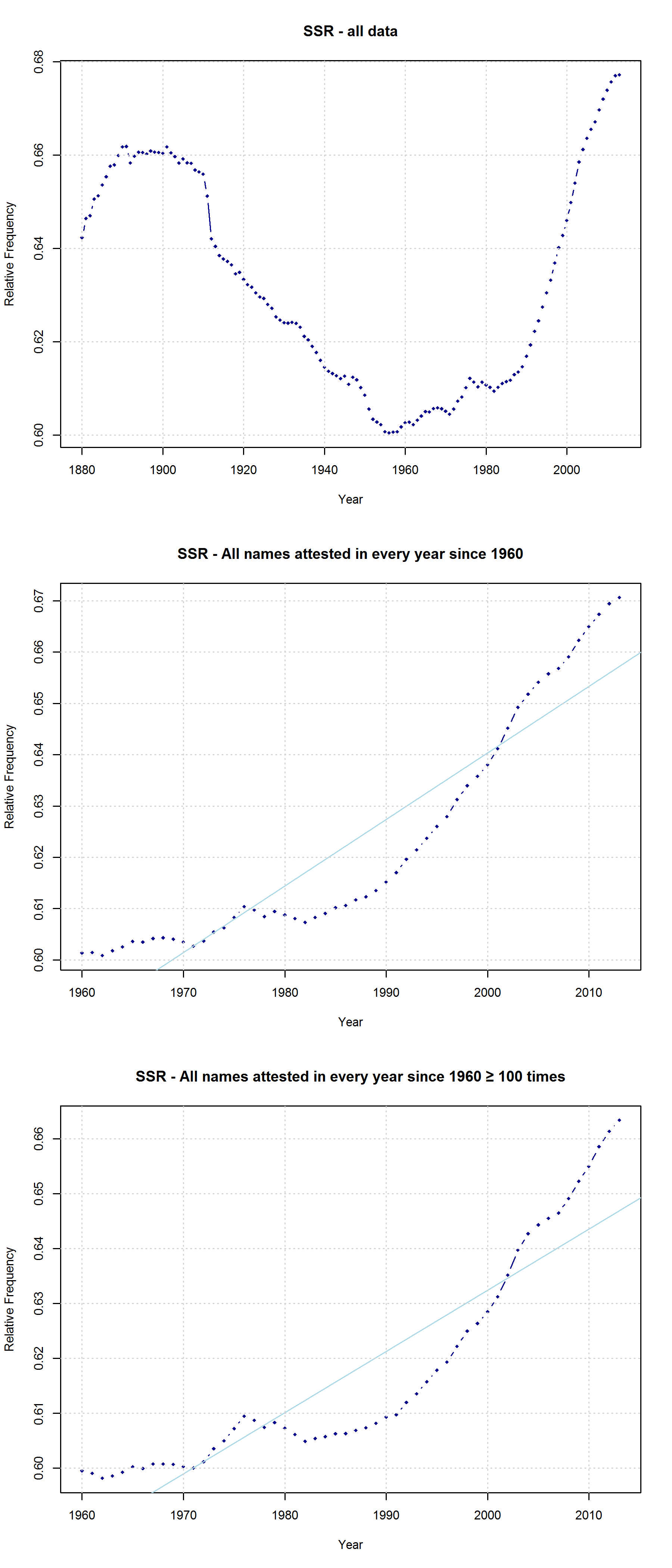
Mark Liberman has already pointed to some problematic aspects of this analysis (but see also Casasanto et al.’s reply). They do not justify why they choose the timeframe of 1960-2012 (although data are available from 1880 onwards), nor do they explain why they only include names given to at least 100 children in each year. Liberman shows that the results look quite different if all available data are taken into account – although, admittedly, an increase in right-side characters from 1990 onwards can still be detected. In their response, Casasanto et al. try to clarify some of these issues. They present an analysis of all names back to 1880 (well, not all names, but all names attested in every year since 1880), and they explain:
“In our longitudinal analysis we only considered names that had been given to more than 100 children in *every year* between 1960 and 2012. By looking at longitudinal changes in the same group of names, this analysis shows changes in names’ popularity over time. If instead you only look at names that were present in a given year, you are performing a haphazard collection of cross-sectional analyses, since many names come and go. The longitudinal analysis we report compares the popularity of the same names over time.“
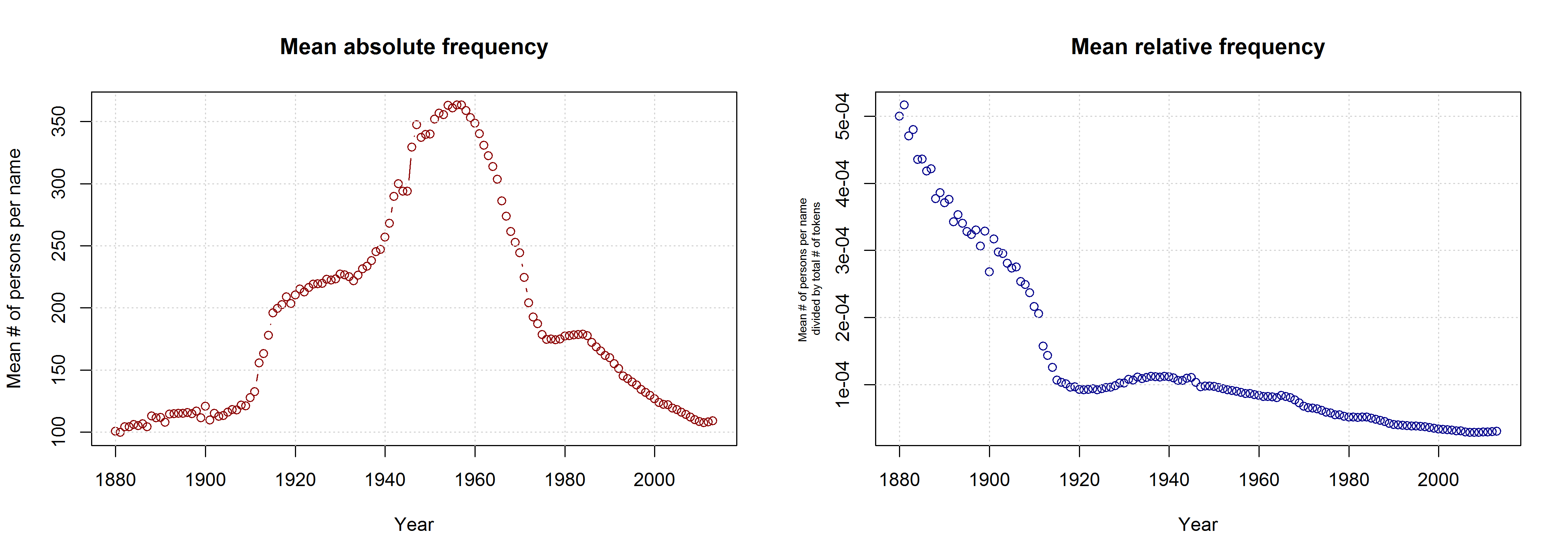
I am not sure what to think of this. On the one hand, this is certainly a methodologically valid approach. On the other hand, I don’t agree that it is necessarily wrong to take all names into account. Given that 3,625 of all name types are attested in every year from 1960 to 2013 and that only 927 of all name types are attested in every year from 1880 to 2013 (the total number of types being 90,979), the vast majority of names is simply not taken into account in Casasanto et al.’s approach. This is all the more problematic given that parents have become increasingly individualistic in naming their children: The mean number of people sharing one and the same name has decreased in absolute terms since the 1960s. If we normalize these data by dividing them by the total number of name tokens in each year, we find that the mean relative frequency of names has continuously decreased over the timespan covered by the SSA data.
Mean frequency of a name (i.e. mean number of people sharing one name) in absolute and relative terms, respectively.
Thus, Casasanto et al. use a sample that might be not very representative of how people name their babies. If the QWERTY effect is a general phenomenon, it should also be found when all available data are taken into account.
As Mark Liberman has already shown, this is indeed the case – although some quite significant ups and downs in the frequency of right-side characters can be detected well before the QWERTY era. But is this rise in frequency from 1990 onwards necessarily due to the spread of QWERTY keyboards – or is there an alternative explanation? Liberman has already pointed to “the popularity of a few names, name-morphemes, or name fragments” as potential factors determining the rise and fall of mean RSA values. In this post, I’d like to take a closer look at one of these potential confounding factors.
Sonorous Sounds and “Soft” Characters
When I saw Casasanto et al.’s data, I was immediately wondering if the change in character distribution could not be explained in terms of phoneme distribution. My PhD advisor, Damaris Nübling, has done some work (see e.g. here [in German]) showing an increasing tendency towards names with a higher proportion of sonorous sounds in Germany. More specifically, she demonstrates that German baby names become more “androgynous” in that male names tend to assume features that used to be characteristic of (German) female names (e.g. hiatus; final full vowel; increase in the overall number of sonorous phonemes). Couldn’t a similar trend be detectable in American baby names?
Names showing particularly strong frequency changes among those names that appear among the Top 20 most frequent names at least once between 1960 and 2013.
If we take a cursory glance at those names that can be found among the Top 20 most frequent names of at least one year since 1960 and if we single out those names that experienced a particularly strong increase or decrease in frequency, we find that, indeed, sonorous names seem to become more popular. Those names that gain in popularity are characterized by lots of vowels, diphthongs (Aiden, Jayden, Abigail), hiatus (Liam, Zoey), as well as nasals and liquids (Lily, Liam).
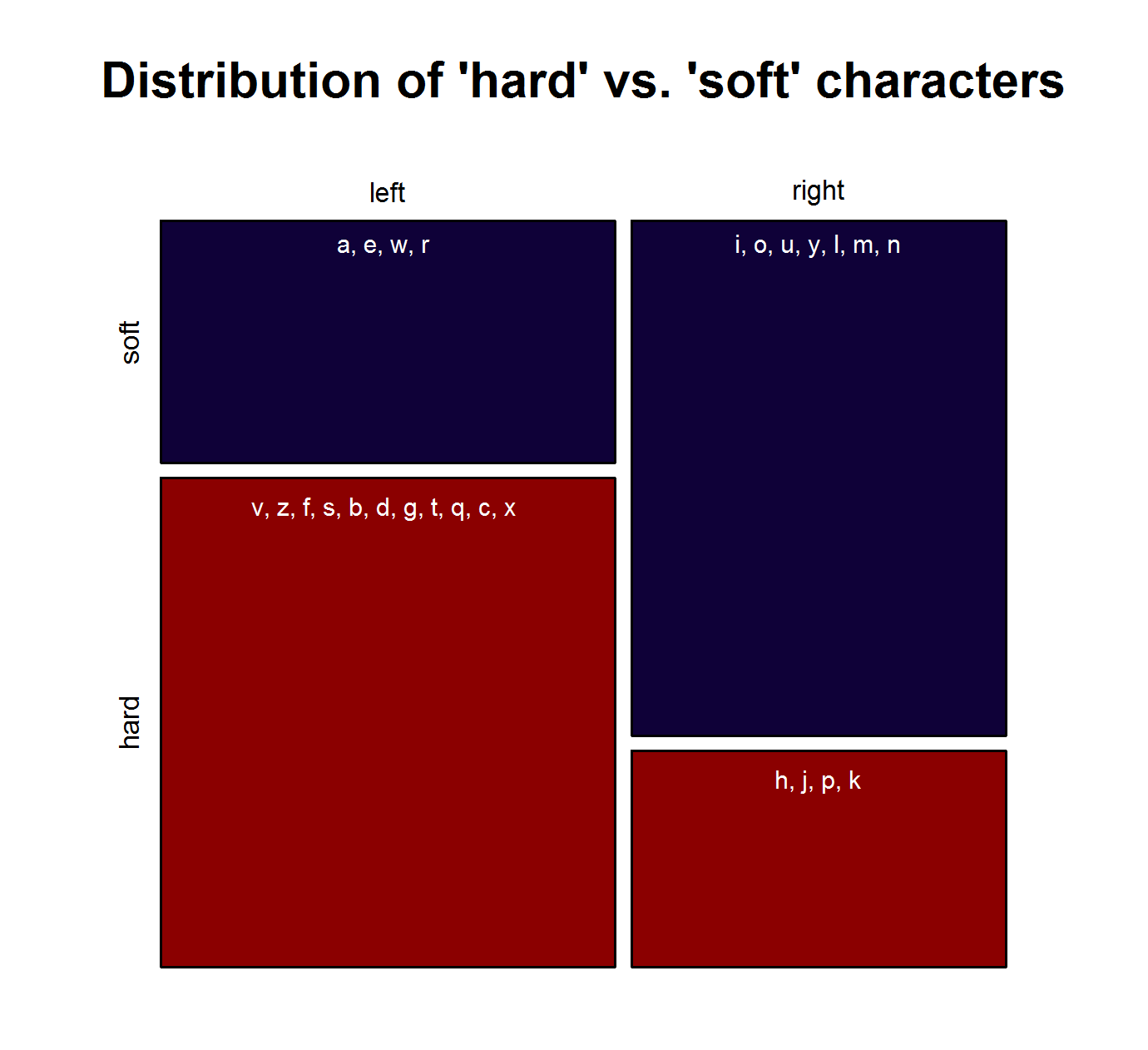
To be sure, these cursory observations are not significant in and of themselves. To test the hypothesis if phonological changes can (partly) account for the QWERTY effect in a bit more detail, I basically split the sonority scale in half. I categorized characters typically representing vowels and sonorants as “soft sound characters” and those typically representing obstruents as “hard sound characters”. This is of course a ridiculously crude distinction entailing some problematic classifications. A more thorough analysis would have to take into account the fact that in many cases, one letter can stand for a variety of different phonemes. But as this is just an exploratory analysis for a blog post, I’ll go with this crude binary distinction. In addition, we can justify this binary categorization with an argument presented above: We can assume that the written representations of words are an important part of the linguistic knowledge of present-day language users. Thus, parents will probably not only be concerned with the question how a name sounds – they will also consider how it looks like in written form. Hence, there might be a preference for characters that prototypically represent “soft sounds”, irrespective of the sounds they actually stand for in a concrete case. But this is highly speculative and would have to be investigated in an entirely different experimental setup (e.g. with a psycholinguistic study using nonce names).
Distribution of “hard sound” vs. “soft sound” characters on the QWERTY keyboard.
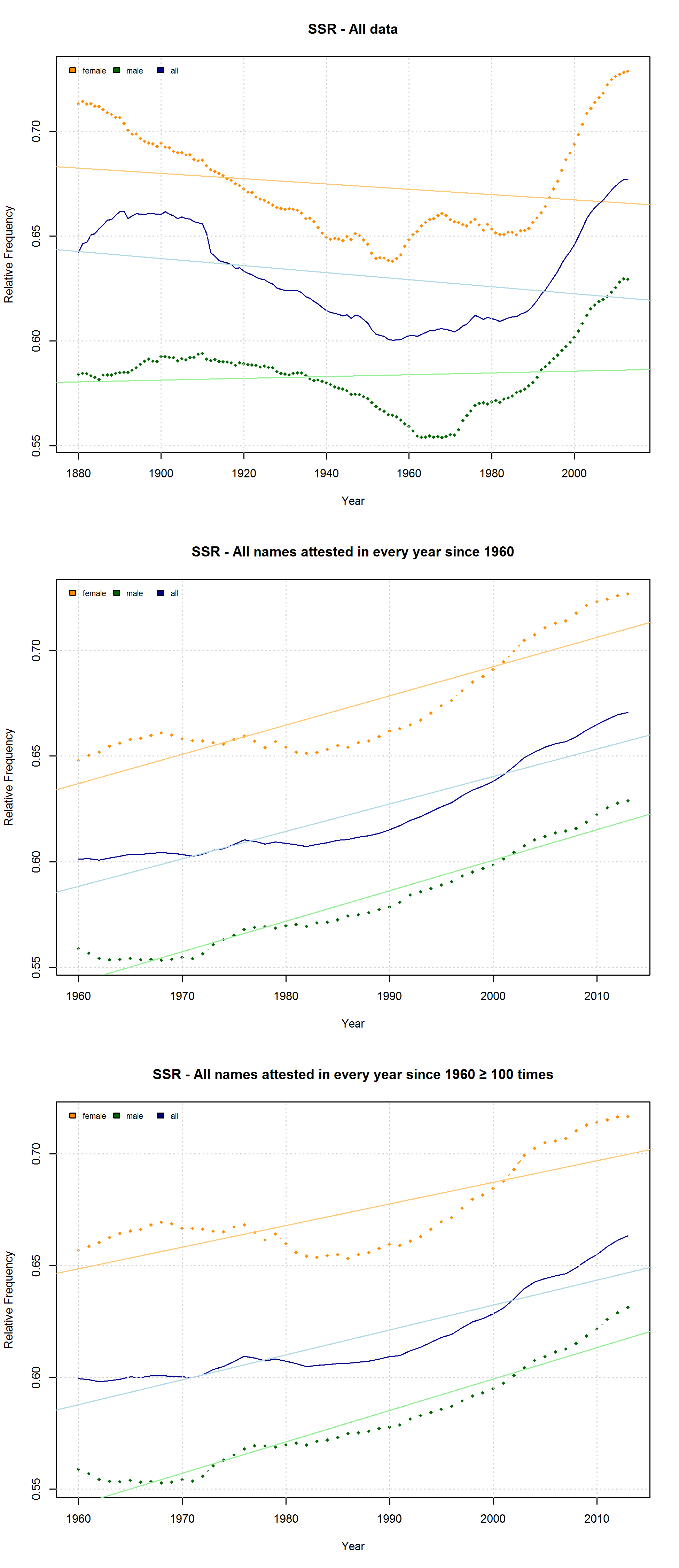
Note that the characters representing “soft sounds” and “hard sounds”, respectively, are distributed unequally over the QWERTY keyboard. Given that most “soft sound characters” are also right-side characters, it is hardly surprising that we cannot only detect an increase in the “Right-Side Advantage” (as well as the “Right-Side Ratio”, see below) of baby names, but also an increase in the mean “Soft Sound Ratio” (SSR – # of soft sound characters / total # of characters). This increase is significant for the time from 1960 to 2013 irrespective of the sample we use: a) all names attested since 1960, b) names attested in every year since 1960, c) names attested in every year since 1960 more than 100 times.
“Soft Sound Ratio” in three different samples: a) All names attested in the SSA data; b) all names attested in every year since 1960; c) all names attested in every year since 1960 at least 100 times.
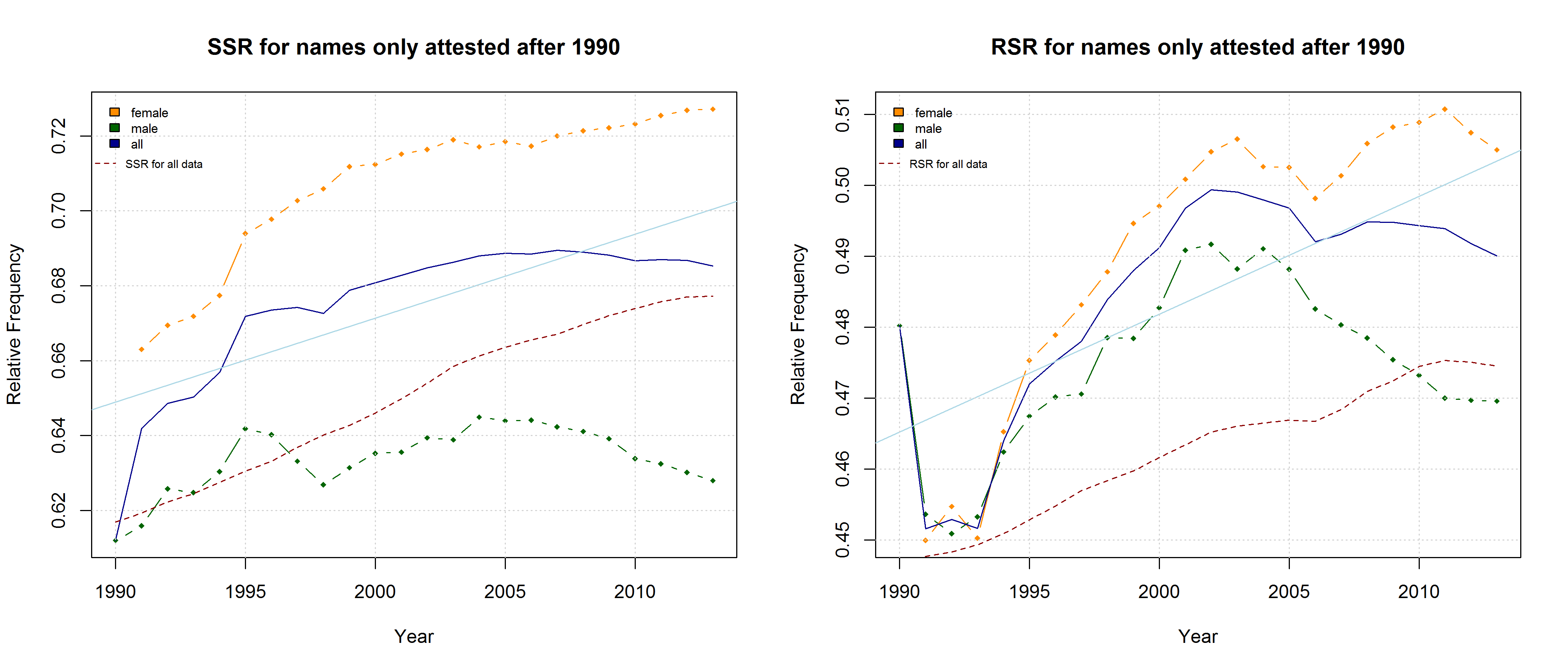
Note that both the “Right-Side Advantage” and the “Soft Sound Ratio” are particularly high in names only attested after 1990. (For the sake of (rough) comparability, I use the relative frequency of right-side characters here, i.e. Right Side Ratio = # of right-side letters / total number of letters.)
“Soft Sound Ratio” and “Right-Side Ratio” for names only attested after 1990.
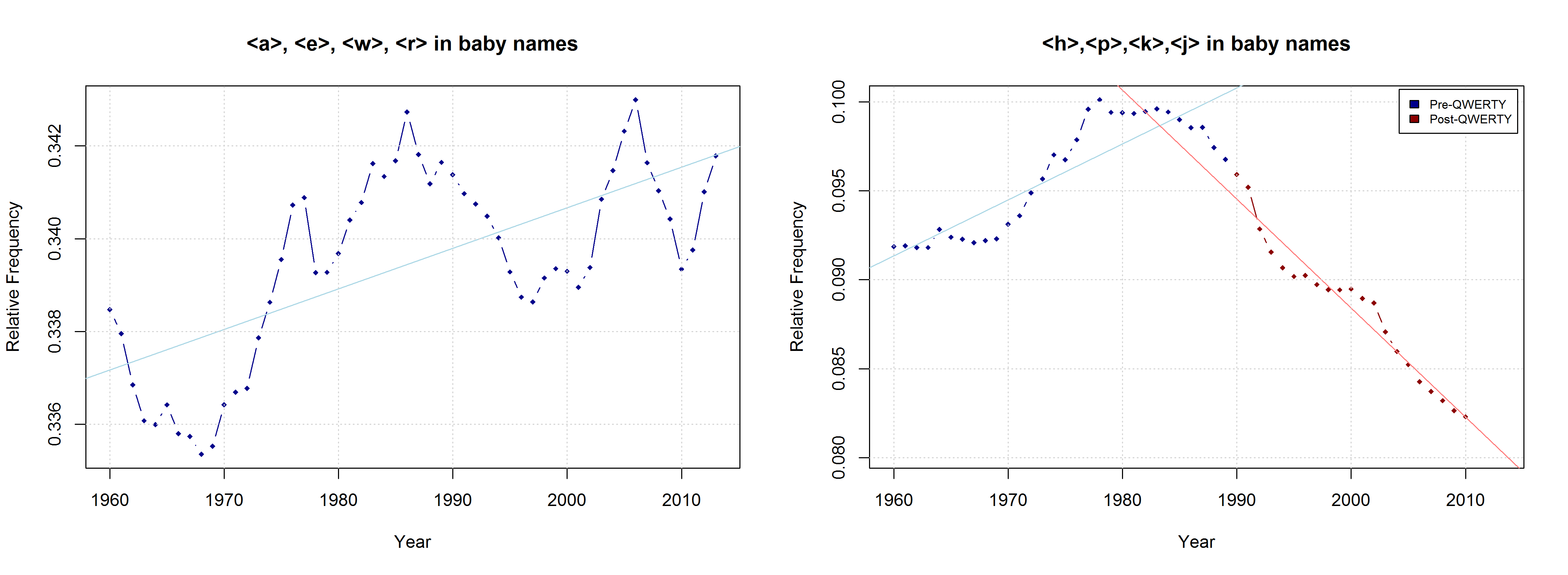
Due to the considerable overlap between right-side and “soft” characters, both the QWERTY Effect and the “Soft Sound” Hypothesis might account for the changes that can be observed in the data. If the QWERTY hypothesis is correct, we should expect an increase for all right-side characters, even those that stand for “hard” sounds. Conversely, we should expect a decrease in the relative frequency of left-side characters, even if they typically represent “soft” sounds. Indeed, the frequency of “Right-Side Hard Characters” does increase – in the time from 1960 to the mid-1980s. In the QWERTY era, by contrast, <h>, <p>, <k>, and <j> suffer a significant decrease in frequency. The frequency of “Left-Side Soft Characters”, by contrast, increases slightly from the late 1960s onwards.
Frequency of left-side “soft” characters and right-side “hard” characters in all baby names attested from 1960 to 2013.
Further potential challenges to the QWERTY Effect and possible alternative experimental setups
The commentors over at Language Log have also been quite creative in coming up with possible alternative explanations and challenging the QWERTY hypothesis by showing that random collections of letters show similarly strong patterns of increase or decrease. Thus, the increase in the frequency of right-side letters in baby names is perhaps equally well, if not better explained by factors independent of character positions on the QWERTY keyboard. Of course, this does not prove that there is no such thing as a QWERTY effect. But as countless cases discussed on Replicated Typo have shown, taking multiple factors into account and considering alternative hypotheses is crucial in the study of cultural evolution. Although the phonological form of words is an obvious candidate as a potential confounding factor, it is not discussed at all in Casasanto et al.’s CogSci paper. However, it is briefly mentioned in Jasmin & Casasanto (2012: 502):
“In any single language, it could happen by chance that words with higher RSAs are more positive, due to sound–valence associations. But despite some commonalities, English, Dutch, and Spanish have different phonological systems and different letter-to-sound mappings.”
While this is certainly true, the sound systems and letter-to-sound mappings of these languages (as well as German and Portugese, which are investigated in the new CogSci paper) are still quite similar in many respects. To rule out the possibility of sound-valence associations, it would be necessary to investigate the phonological makeup of positively vs. negatively connotated words in much more detail.
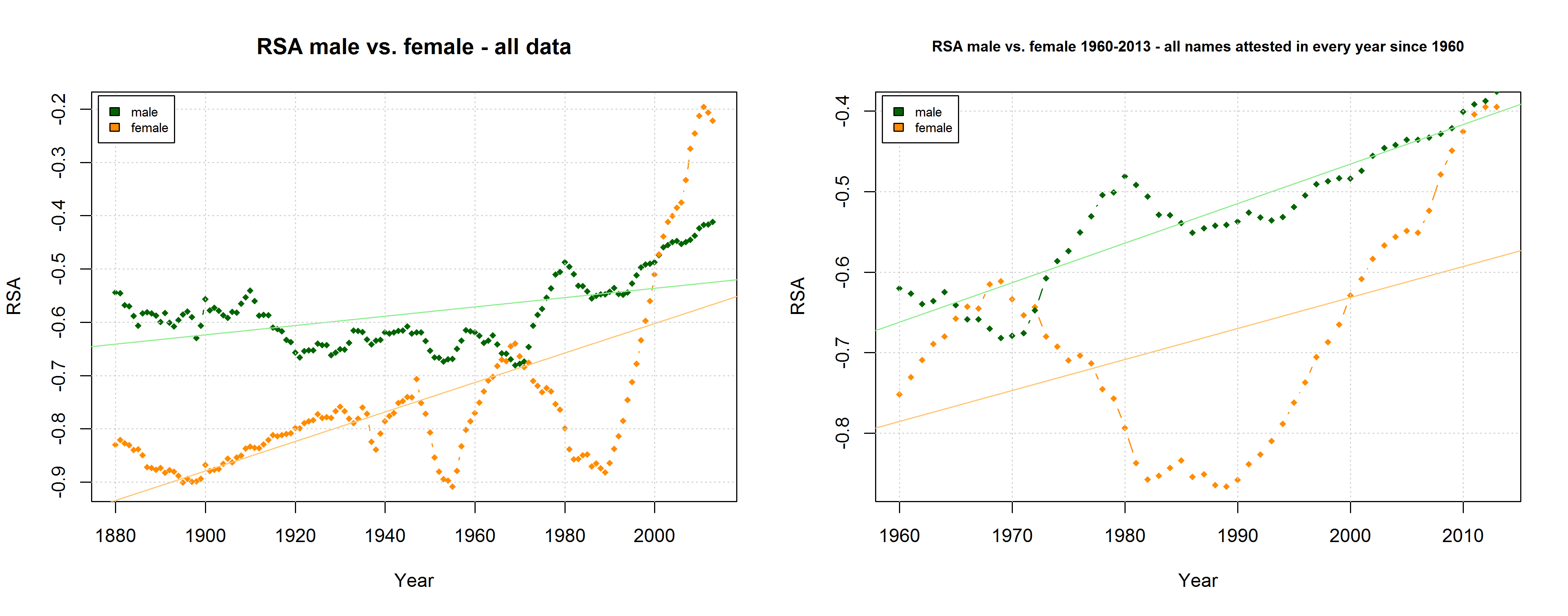
Right-Side Advantage (RSA) for male vs. female names in two different samples (all names attested in the SSA data and all names attested in every year since 1960).
The SSA name lists provide another means to critically examine the QWERTY hypothesis since they differentiate between male and female names. If the QWERTY effect does play a significant role in parents’ name choices, we would expect it to be equally strong for boys names and girls names – or at least approximately so.
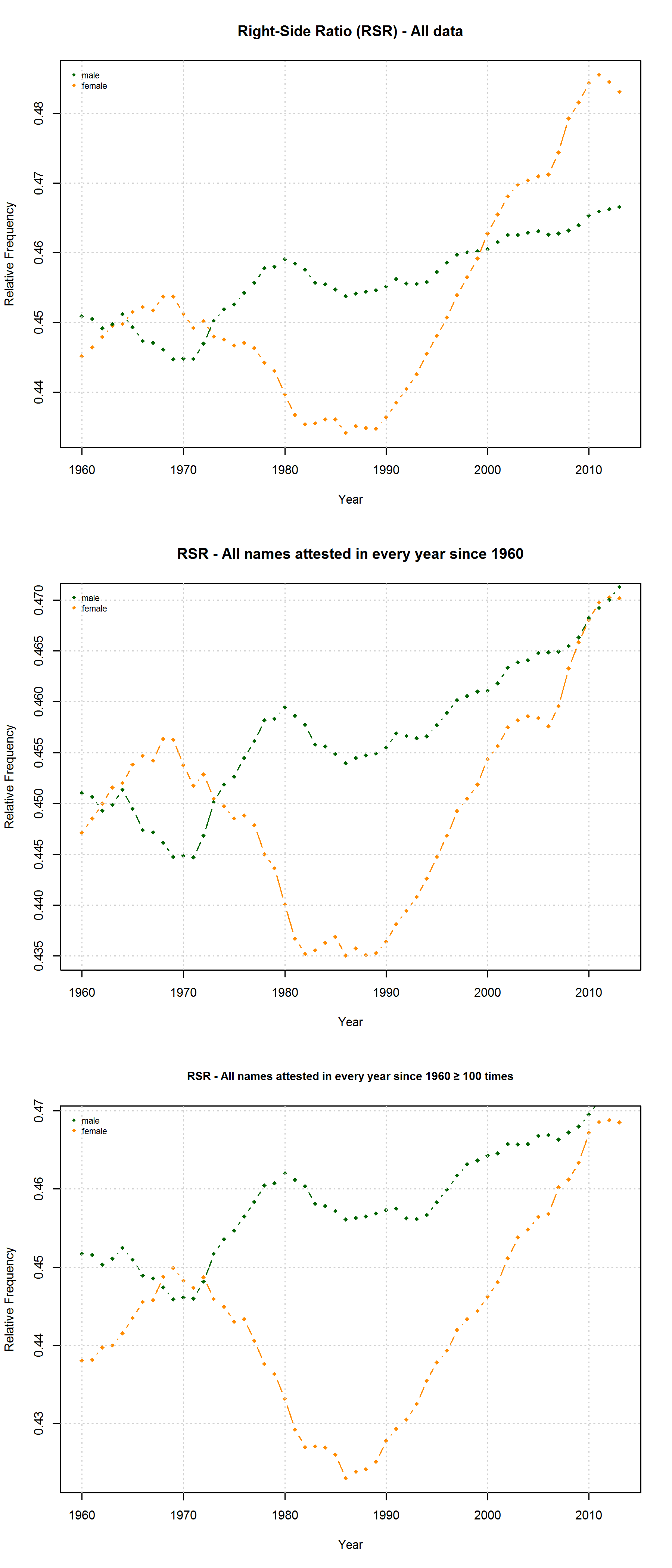
Right-Side Ratio for three different samples (all names attested in the SSA lists, all names attested in every year since 1960, all years attested in every year since 1960 at least 100 times).
On the hypothesis that other factors such as trend names play a much more important role, by contrast, differences between the developments of male vs. female names are to be expected. Indeed, the data reveal some differences between the RSA / RSR development of boys vs. girls names. At the same time, however, these differences show that the “Soft Sound Hypothesis” can only partly account for the QWERTY Effect since the “Soft Sound Ratios” of male vs. female names develop roughly in parallel.
“Soft Sound Ratio” of male vs. female names .
Given the complexity of cultural phenomena such as naming preferences, we would of course hardly expect one factor alone to determine people’s choices. The QWERTY Effect, like the “Soft Sound” Preference, might well be one factor governing parents’ naming decisions. However, the experimental setups used so far to investigate the QWERTY hypothesis are much too prone to spurious correlations to provide convincing evidence for the idea that words with a higher RSA assume more positive valences because of their number of right-side letters.
Granted, the amount of experimental evidence assembled by Casasanto et al. for the QWERTY effect is impressive. Nevertheless, the correlations they find may well be spurious ones. Don’t get me wrong – I’m absolutely in favor of bold hypotheses (e.g. about Neanderthal language). But as a corpus linguist, I doubt that such a subtle preference can be meaningfully investigated using corpus-linguistic methods. As a corpus linguist, you’re always dealing with a lot of variables you can’t control for. This is not too big a problem if your research question is framed appropriately and if potential confounding factors are explicitly taken into account. But when it comes to a possible connection between single letters and emotional valence, the number of potential confounding factors just seems to outweigh the significance of an effect as subtle as the correlation between time and average RSA of baby names. In addition, some of the presumptions of the QWERTY studies would have to be examined independently: Does the average QWERTY user really use their left hand for typing left-side characters and their right hand for typing right-side characters – or are there significant differences between individual typing styles? How fluent is the average QWERTY user in typing? (The question of typing fluency is discussed in passing in the 2012 paper.)
The study of naming preferences entails even more potentially confounding variables. For example, if we assume that people want their children’s names to be as beautiful as possible not only in phonological, but also in graphemic terms, we could speculate that the form of letters (round vs. edgy or pointed) and the position of letters within the graphemic representation of a name play a more or less important role. In addition, you can’t control for, say, all names of persons that were famous in a given year and thus might have influenced parents’ naming choices.
If corpus analyses are, in my view, an inappropriate method to investigate the QWERTY effect, then what about behavioral experiments? In their 2012 paper, Jasmin & Casasanto have reported an experiment in which they elicited valence judgments for pseudowords to rule out possible frequency effects:
“In principle, if words with higher RSAs also had higher frequencies, this could result in a spurious correlation between RSA and valence. Information about lexical frequency was not available for all of the words from Experiments 1 and 2, complicating an analysis to rule out possible frequency effects. In the present experiment, however, all items were novel and, therefore, had frequencies of zero.”
Note, however, that they used phonologically well-formed stimuli such as pleek or ploke. These can be expected to yield associations to existing words such as, say, peak connotated) and poke, or speak and spoke, etc. It would be interesting to repeat this experiment with phonologically ill-formed pseudowords. (After all, participants were told they were reading words in an alien language – why shouldn’t this language only consist of consonants?) Furthermore, Casasanto & Chrysikou (2011) have shown that space-valence mappings can change fairly quickly following a short-term handicap (e.g. being unable to use your right hand as a right-hander). Considering this, it would be interesting to perform experiments using a different kind of keyboard, e.g. an ABCDE keyboard, a KALQ keyboard, or – perhaps the best solution – a keyboard in which the right and the left side of the QWERTY keyboard are simply inverted. In a training phase, participants would have to become acquainted with the unfamiliar keyboard design. In the test phase, then, pseudowords that don’t resemble words in the participants’ native language should be used to figure out whether an ABCDE-, KALQ-, or reverse QWERTY effect can be detected.
References
Casasanto, D. (2009). Embodiment of Abstract Concepts: Good and Bad in Right- and Left-Handers. Journal of Experimental Psychology: General 138, 351–367.
Casasanto, D., & Chrysikou, E. G. (2011). When Left Is “Right”. Motor Fluency Shapes Abstract Concepts. Psychological Science 22, 419–422.
Casasanto, D., Jasmin, K., Brookshire, G., & Gijssels, T. (2014). The QWERTY Effect: How typing shapes word meanings and baby names. In P. Bello, M. Guarini, M. McShane, & B. Scassellati (Eds.), Proceedings of the 36th Annual Conference of the Cognitive Science Society. Austin, TX: Cognitive Science Society.
Jasmin, K., & Casasanto, D. (2012). The QWERTY Effect: How Typing Shapes the Meanings of Words. Psychonomic Bulletin & Review 19, 499–504.
Littauer, R., Roberts, S., Winters, J., Bailes, R., Pleyer, M., & Little, H. (2014). From the Savannah to the Cloud. Blogging Evolutionary Linguistics Research. In L. McCrohon, B. Thompson, T. Verhoef, & H. Yamauchi, The Past, Present, and Future of Language Evolution Research. Student Volume following the 9th International Conference on the Evolution of Language (pp. 121–131).
Nübling, D. (2009). Von Monika zu Mia, von Norbert zu Noah. Zur Androgynisierung der Rufnamen seit 1945 auf prosodisch-phonologischer Ebene. Beiträge zur Namenforschung 44.